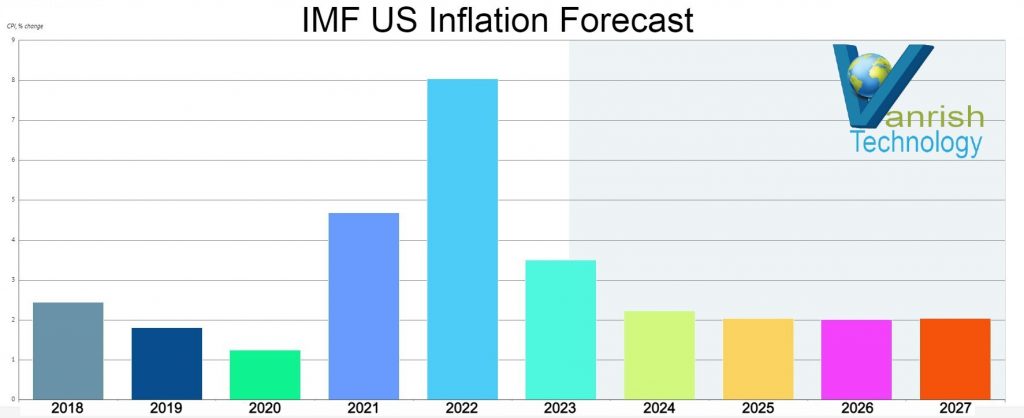
Global uncertainties continue to dominate headlines. Inflation is expected to reach the highest levels of ~3.5% in the US and Europe by the end of 2023. To ease inflation, Central Banks need to dampen demand, by making it expensive (for financial institutions, businesses and households) to borrow by increasing Federal Reserve interest rates . We are expecting a federal rate hike of 4.75% – 5.0% by the end of 2023. These are all data showing we are heading toward recession. The US labor market was robust last quarter but this quarter it is not very promising. Everyday we are hearing layoff news from different sectors.
IMF inflation forecast
These inflation and layoff news are impacting our tech market. Many companies have a growth challenge: They expect to get as much as 50 percent of their revenue from new businesses and products by 2026 but are not on a path that will take them there. Current economic conditions are forcing high-growth yet unprofitable tech startups to tighten their financial belts.
There are few realities, software companies are facing for their growth.
US-based Venture capitalists backed software startups slowed down – VC are very clear of high valuation and demanding that companies spend less, improve profit margin and high output. Unicorn creation also slowed in 2022 Q4. This is one of the lowest quarterly count since the first quarter of 2020.
Depressed company valuations – Private company valuations are cooling down. Over the last 4 quarters, we have seen public valuations compressing.
Software companies have three critical revenue streams.
License / Subscription Revenue – When the customer pays for the right to own and use a copy of the software/hardware product or subscribe/access software platform
software or hardware product – Customer pays for ongoing support or premium support.
Cloud based licensed software – Customer pays the software provider for specific deliverables such as software implementation or technical training.
In the current world all these 3 revenue streams are shrinking. Companies are using only essential services to run their business. This is directly impacting software revenue, which is leading these companies into low valuation.
Infrastructure Maintenance – SaaS companies are providing the software as a service. This means the customer does not have to purchase hardware to run the software—that cost is transferred to the SaaS provider. This is implying continuous software running coast. This cost is not going anywhere.So due to inflation this SaaS running cost increases tremendously.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
API is a key component of digital transformation. API is the interface of your legacy and SAAS data. The goal of APIs is to facilitate the transfer and enablement of data between your system and external users. APIs are typically available through public networks like the internet to communicate to external users and expose your data into the public domain.
Since your data is exposed into the public domain through APIs, It can lead to a data breach. APIs can be broken and expose sensitive personal as well as company data. An insecure API can be an easy target for hackers to gain access to your system and network. Rise of IOT devices and usage of APIs by these IOT devices, APIs are now more vulnerable.
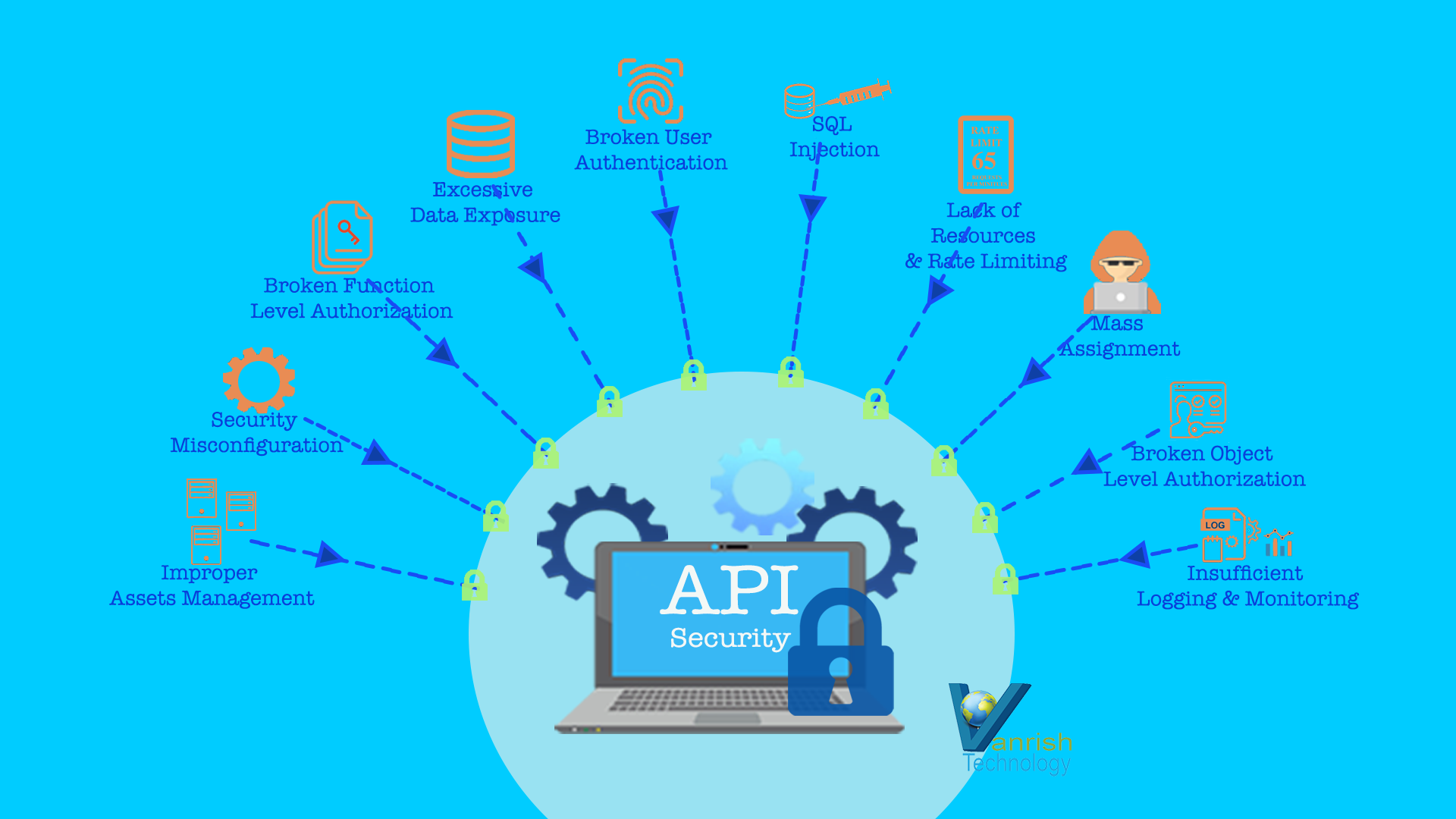
According to owasp, these are 10 main API vulnerabilities.
Broken Object Level Authorization – Expose endpoints that handle object identifiers, creating a wide attack surface Level Access Control issue.
Broken User Authentication – Authentication mechanisms are implemented incorrectly.
Excessive Data Exposure – Developers expose all object properties without considering their individual sensitivity
Lack of Resources & Rate Limiting – APIs do not impose any restrictions on the size or number of resources that can be requested by the client/user, lead to Denial of Service (DoS) attack on APIs
Broken Function Level Authorization– Complex access control policies with different hierarchies lead to authorization flaws.
Mass Assignment – Without proper properties filtering based on an allowlist, usually leads to Mass Assignment.
Security Misconfiguration – Misconfiguration or lack of Security configuration is commonly a result of insecure APIs
SQL Injection– SQL Injection occurs when untrusted data is sent to an interpreter as part of a command or query.
Improper Assets Management – APIs tend to expose more endpoints than traditional web applications lead to improper expose APIs.
Insufficient Logging & Monitoring – Insufficient logging and monitoring fail to find your vulnerability and broken integration.
How to mitigate API security risk?
API supports secure sockets layer (SSL), transport layer security (TLS), and Hypertext Transfer Protocol Secure (HTTPS) protocols, which provide security by encrypting data during the transfer process.
Apply Basic Auth minimum with API or if you want to more secure your API then enable 2 way authentication through OAuth framework .
Apply Authorization on each API resource to more control on API security through external Identity and access management provider (IAM).
Use encryption and signatures to all your API exposed personal and organizational sensitive data.
Apply API throttling through API manager to control number of user access per API (Rate Limiting).
Implement best practice of exception handling on your APIs to hide all your internal server and database information to mitigate SQL injection security risk.
Use Service Mesh to manage different layers of API management and control.
Audit your APIs and remove all unused API from your API catalog.
Add proper logging, Monitoring and Alerting on your APIs to keep track of your APIs activity.
Conclusion: APIs are a critical part of modern AI, mobile, SaaS, IOT and web applications. APIs Security should be the main focus on strategies and solutions to mitigate the unique vulnerabilities and security risks .
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Keep the application synchronous if possible. Synchronous flows avoid serialization/deserialization of messages sent through VM queues, do not cause context switches, and do not cause contention when messages move across thread pools.
Store as little as possible in variables. The vars are serialized and deserialized every time a message crosses an endpoint, even if it is a VM endpoint. This will impact performance overhead in direct proportion to the size of variables and the number of endpoints.
Use Dataweave Java payloads whenever possible. The usage of a canonical data model is recommended for projects that deal with data (mapping, transformation etc.). It is also recommended to create them in Java objects as dataweave whenever possible, as this provides the fastest format to access fields and change information and to convert to other formats.
Encourage dataweave languages. For better performance, use Dataweave for simple data extraction from messages, and Java components with dataweave for everything else.
Use flow references instead of VM endpoints. To communicate between flows internally within an application, use flow references instead of VM endpoints. The VM connector, even though it is an in-memory protocol, emulates transport semantics that serialize and deserialize parts of your messages, most notably the vars. This makes it slower than a flow reference, which just injects messages into the referenced flow with no intermediate steps. Please note that in some cases the usage of VM endpoints is preferred (see the chapter on reliability patterns). For example, a Mule cluster can load balance applications that use VM endpoints by deferring execution to another, available node in the cluster.
Cache aggressively. Take advantage of Mule’s caching scope when making requests to external resources like Web services or databases. Also consider caching reusable assets such as security tokens or ephemeral API keys and cookies. Mule’s Notification subsystem can additionally be used to “warm up” a cache when Mule starts. For example, consider doing this for situations where an initial cache miss is not acceptable.
Configure message processors and endpoints at the global level. Some connectors allow you to configure some parameters at both the global and the endpoint/message processor level. We recommend placing the configuration at a global level to avoid repeated initialization of resources.
Avoid creating a large volume of business events. Business events incur performance overhead in Mule and in platform when platform’s internal event buffer overflows. Thus, avoid using either default flow level business events or a large volume of custom business events in a high message volume project.
Consider using message compression. For communicating between Mule applications over the network consider using Mule’s compression processors to compress/decompress the message payloads before they hit the wire if their sizes are large.
Consider using VM queues instead of an external message broker. VM queues are fast and have some guaranteed delivery semantics in a cluster. Consider using these instead of going out to an external messaging broker for inter-application Mule communication.
Use the async scope when appropriate. If a flow is performing processing on a message that is neither modifying the message nor changing how it is routed, then it could be wrapped in an async block. This will cause the processing to occur in a different thread and will avoid adding unnecessary overhead to processing the message.
Use connection pooling for connectors because the performance cost of establishing a connection to another data source, such as a database, is relatively high.
Optimize your logging within your mule flows. Too much logging will slow down your process and too less logging will hard to debug.
Encryption and decryption of data is very costly. Whenever your Mule application really needs then apply encryption/decryption on your data.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Mule 4 introduced APIKit for soap webservice. It is very similar to APIKit for Rest. In SOAP APIKit, it accepts WSDL file instead of RAML file. APIKit for SOAP generates work flow from remote WSDL file or downloaded WSDL file in your system.
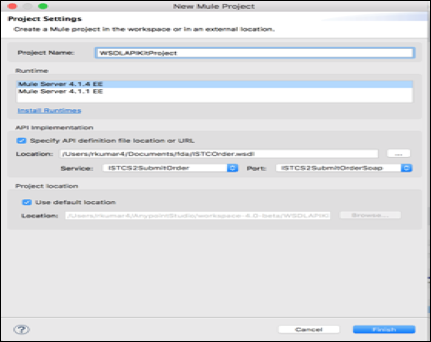
To create SOAP APIKit project, First create Mulesoft project with these steps in Anypoint studio.
Under File Menu -> select New -> Mule Project
Mule 4 Project Settings
In above pic WSDL file gets selected from local folder to create Mule Project.
Once you click finish, it generates default APIKit flow based on WSDL file.
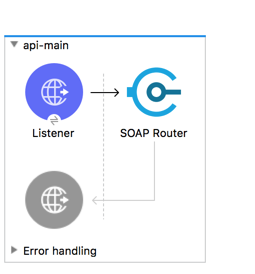
In this Mulesoft SOAP APIKit example project, application is consuming SOAP webservice and exposing WSDL and enabling SOAP webservice.
Mule 4 API Kit for Soap Router
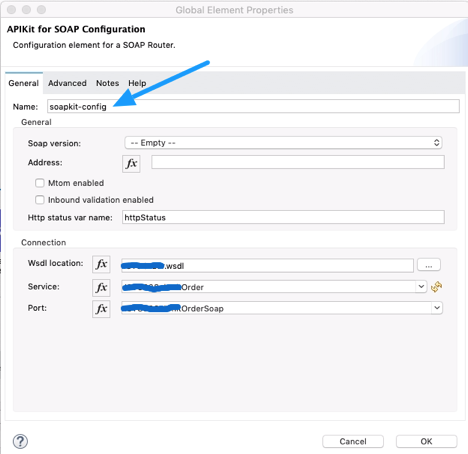
In SOAP Router APIKit, APIKit SOAP Configuration is defined WSDL location, Services and Port from WSDL file.
API Kit SOAP configuration
In above configuration, “soapkit-config” SOAP Router look up for requested method. Based on requested method it reroutes request from api-main flow to method flow. In this example, requested method is “ExecuteTransaction” from existing wsdl, so method flow name is
<flow name=“ExecuteTransaction:\soapkit-config”>
In this example we are consuming same WSDL but end point is different.
To call same WSDL we have to format our request based on WSDL file. In dataweave, create request based on WSDL and sending request through HTTP connector.
Here is dataweave transformation to generate request for existing WSDL file
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Much awaited Mulesoft 4 was officially announced in Mulesoft
Connect 2018 in San Jose. When Mulesoft was born, it was really to create
software that helps to interact systems or source of information quickly within
or outside company. So the speed is an incredibly important thing over the
years to develop and interact within systems. Need of speed for application and
development hasn’t change drastically over the years but needs and requirement
of customer’s application have changed. The integration landscape has also
magnified. There are hundreds of new systems and sources of information to
connect to, with more and more integration requirements. This integration
landscape gets very messy and very quickly.
Mule 4 provides
a simplified language, simplified runtime engine and ultimately reduces
management complexity. It helps
customers, developers to deliver application faster. Mule4 is really radically
simplified development. It is providing new tool to simplify your development,
deployment and management of your integration/API. It is also providing a
platform to reuse Mule component without affecting existing application for
faster development. Mule 4 is evolution of Mule3. You will not seem lost in
Mule 4, if you are coming from Mule3. But Mule 4 implements fewer concepts and
steps to simplify whole development/integration process. Mule 4 has now java
skill is optional. In this release Mulesoft is improving tool and making error
reporting more robust and platform independent.
Now let’s go one by one with all these new Mule4 features.
1. Simplified
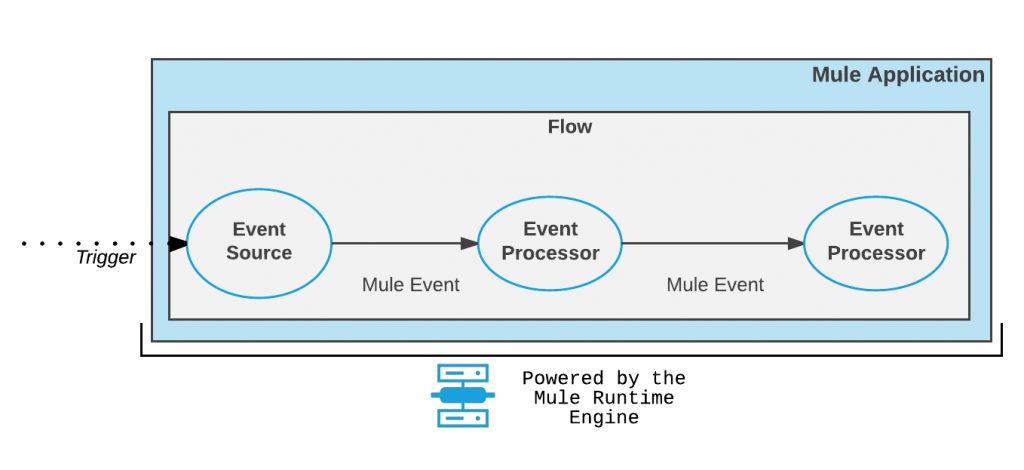
Event Processing and Messaging — Mule event is
immutable, so every change to an instance of a Mule event results in the
creation of a new instance.It contains the core
information processed by the runtime. It travels through components inside your
Mule app following the configured application logic. A Mule event is generated when a trigger (such as an
HTTP request or a change to a database or file) reaches the Event source of a
flow. This trigger could be an external event triggered by a resource that
might be external to the Mule app.
Mule 4 Event flow
2. New
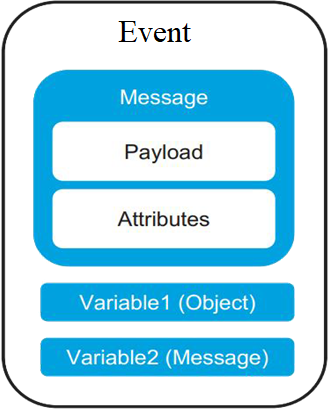
Event and Message structure — Mule 4 includes a
simplified Mule message model in which each Mule event has a message and
variables associated with it. A Mule message is
composed of a payload and its attributes (metadata, such as file size).
Variables hold arbitrary user information such as operation results, auxiliary
values, and so on.
Mule 4 message
Mules 4 do not have Inbound, Outbound and Attachment
properties like Mule 3. In mule 4 all information
are saved in variables and attributes. Attributes in Mule 4 replace inbound properties. Attributes
can be easily accessed through expressions.
These
are advantages to use Attributes in
Mule 4.
They are strongly typed, so you can easily see
what data is available.
They can easily be stored in variables that you
can access throughout your flow
Example :
#[attributes.uriParams.jobnumber]
Outbound properties— Mule 4 has no concept for outbound properties like in Mule 3. So you can set status code response or header information in Mule 4 through Dataweave expression without introducing any side effects in the main flow.
Session Properties–In Mule 4 Session properties are no longer exist. Data store in variables are passes along with different flow.
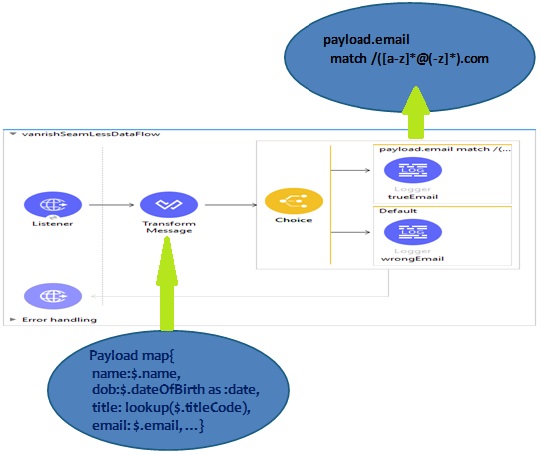
3. Seamless data access & streaming – Mule 4 has fewer concepts and steps. Now every steps and task of java language knowledge is optional.Mule 4 is not only leveraging DataWeave as a transformation language, but expression language as well. For example in Mule 3 XML/CSV data need to be converted into java object to parse or reroute them. Mule 4 gives the ability to parse or reroute through Dataweave expression without converting into java. These steps simplify your implementation without using java.
Mule 4 Data Access
4. Dataweave 2.0 — Mule 4 introduces DataWeave as the default
expression language replacing Mule Expression Language (MEL) with a scripting
and transformation engine. It is combined with the built-in streaming
capabilities; this change simplifies many common tasks. Mule 4
simplifies data iteration. DataWeave knows how to iterate a json array. You
don’t even need to specify it is json. No need to use <json:json-to-object-transformer /> to convert data into java object.
Mule 4 vs Mule 3 flow comparison
Here are few points about Dataweave 2.0
Simpler syntax to learn
Human readable descriptions of all data types
Applies complex routing/filter rules.
Easy access to payload data without the need for
transformation.
Performs any kind of data transformation,
normalization, grouping, joins, pivoting and filtering.
5. Repeatable
Streaming – Mule 4 introduces
repeatable streams as its default framework for handling streams. To understand
the changes introduced in Mule 4, it is necessary to understand how Mule3 data
streams are consumed
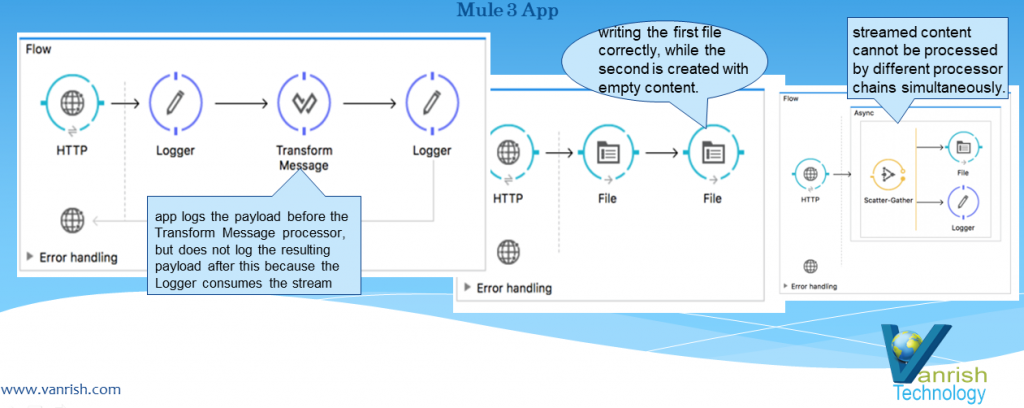
Mule 3 data streaming examples
In above three different Mule 3 flows, once stream data is
consumed by one node it is empty stream for 2nd node. So in the above
first example, in order to log the stream payload , the logger has to consume
the entire stream of data from HTTP connector. This means that the full content
will be loaded into memory. So if the content is too big and you’re loading
into memory, there is a good chance the application might run out of memory.
So Mule 4 repeatable streams enable you to
Read a stream more than once
Have concurrent access to the stream.
Random Access
Streams of bytes or streams of objects
As a component consumes the stream, Mule saves its content
into a temporary buffer. The runtime then feeds the component from the
temporary buffer, ensuring that each component receives the full stream,
regardless of how much of the stream was already consumed by any prior
component
Here are few points, how repeatable streams works in Mule 4
Payload
is read into memory as it is consumed
If
payload stream buffer size is > 512K (default) then it will be persisted to
disk.
Payload
stream buffer size can be increased or decreased by configuration to optimize
performance
Any
stream can be read at any random position, by any random thread concurrently
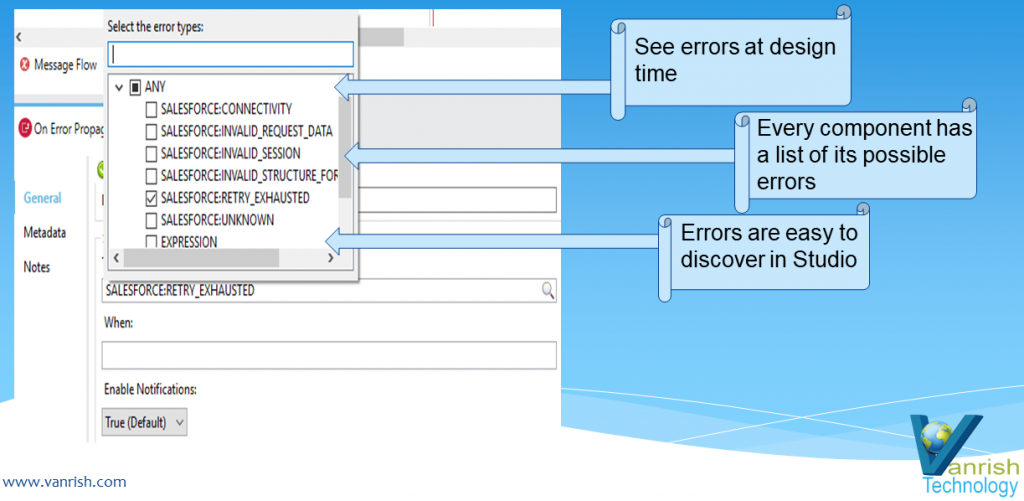
6. Error Handling — In Mule 4 error handling has been changed
significantly. Now In mule 4 you can discover errors at design time with visual
interface. You no need to deal with java exception directly and it is easy to
discover error while you are building flow. Every flow listed all possible
exception which potential arises during execution.
Mule 4 Error Handling
Now errors that occur
in Mule fall into two categories
Messaging errors
System errors
Messaging errors — Mule throws a messaging error (a Mule error) whenever a problem occurs within a flow. To handle Mule
errors, you can set up On Error components inside the scope-like Error Handler
component. By default, any unhandled errors are logged and propagated.
System errors — Mule throws a system error when an exception occurs
at the system level . If no Mule Event is involved, the errors are handled by a
system error handler.
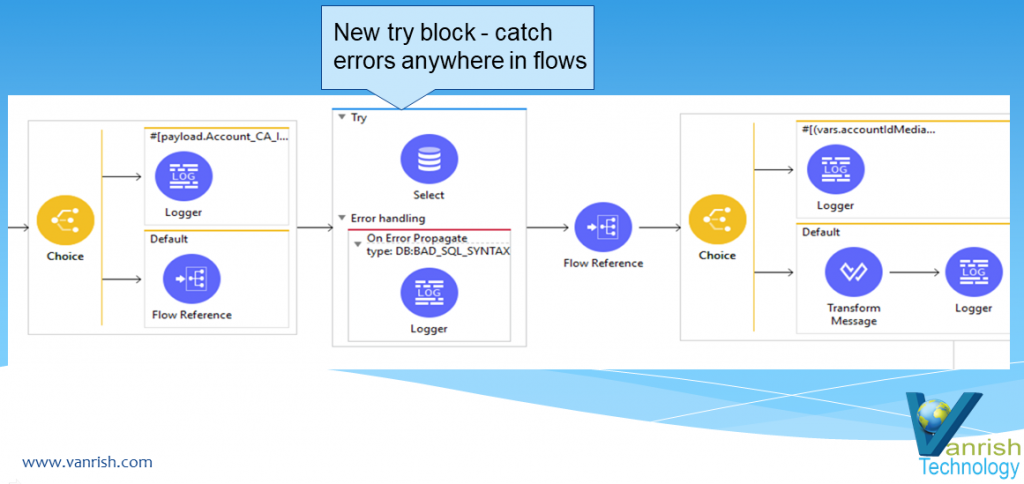
Try catch Scope — Mule 4 introduces a new try scope that you can use within a flow to do error handling of just inner components/connectors. This try scope also supports transactions and in this way it is replacing Old Mule 3 transaction scope.
Mule 4 A new try catch block
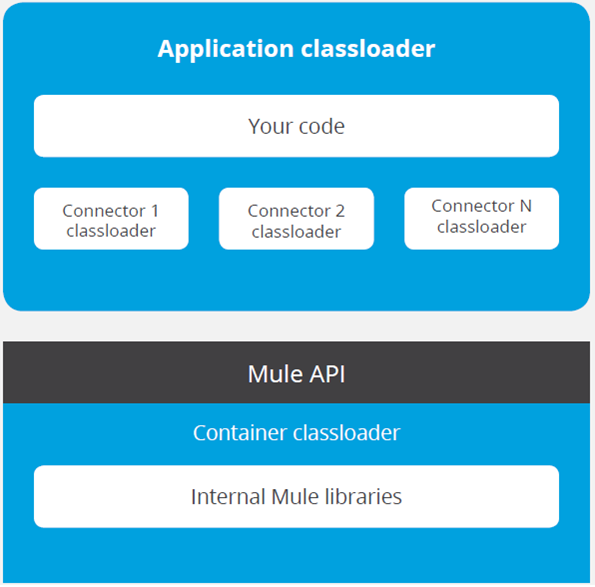
7. Class Loader Isolation — Class loader separates application completely from
Mule runtime and connector runtime. So, library file changes (jar version) do
not affect your application. This also
gives flexibility to your application to run any Spring version without worry
about Mulesoft spring version. Connectors are distributed outside the runtime
as well, making it possible to get connector enhancements and fixes without
having to upgrade the runtime or vice versa
In above pic showing that every component in any application have their own class loader and running independently on own class loader.
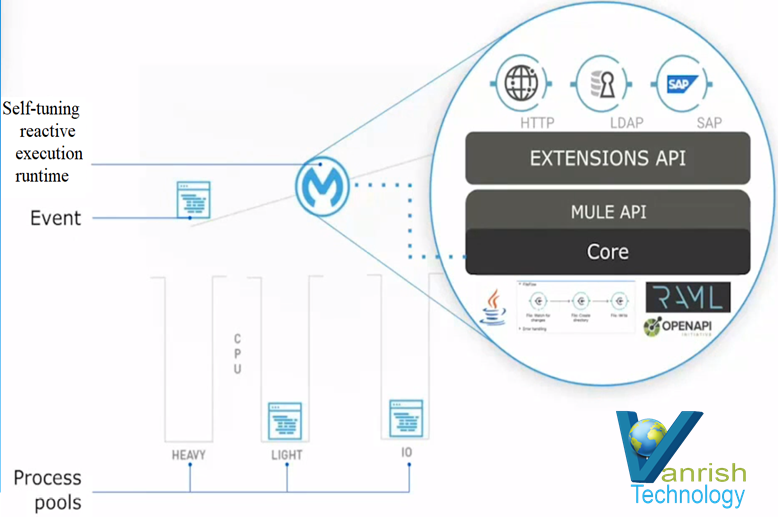
8. Runtime Engine — Mule 4 engine is new reactive and non-blocking engine. In Mule 4 non-blocking flow always on, so no processing strategy in flow. One best feature of Mule 4 engine is, It is self-tuning runtime engine. So what does this mean? If Mule 4 engine is processing your applications on 3 different thread pools, So runtime knows which application should be executed by each thread pool. So operation put in corresponding thread pool based on high intensive CPU processing or light intensive CPU processing or I/O operation. Then 3 pools are dynamic resizing automatically to execute application through self-tuning.
Mule 4 : Self tuning run time engine
So now self-tuning creates custom thread pools based on specific tasks. Mule 4 engine makes it possible to achieve optimal performance without having to do manual tuning steps.
Conclusion
Overall Mule 4 is
trying to make application development easy, fast and robust. There are more features
included in Mule 4 which I will try to cover in my next blog. I will also try
to cover more in depth info in above topic of Mule 4. Please keep tuning for my
next blog.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.