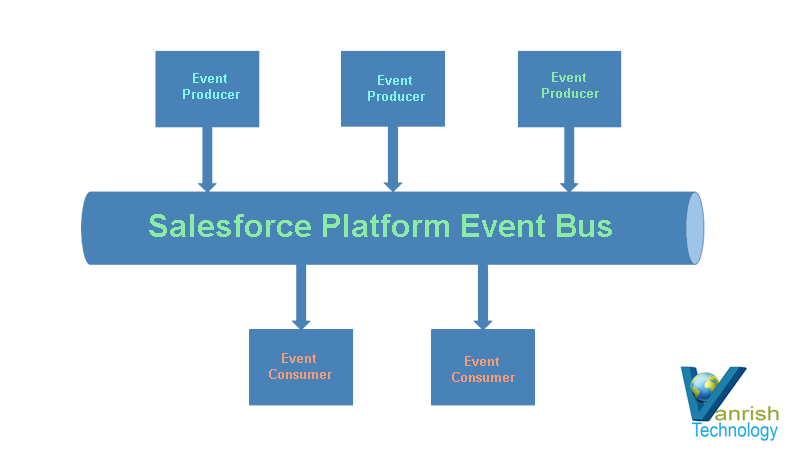
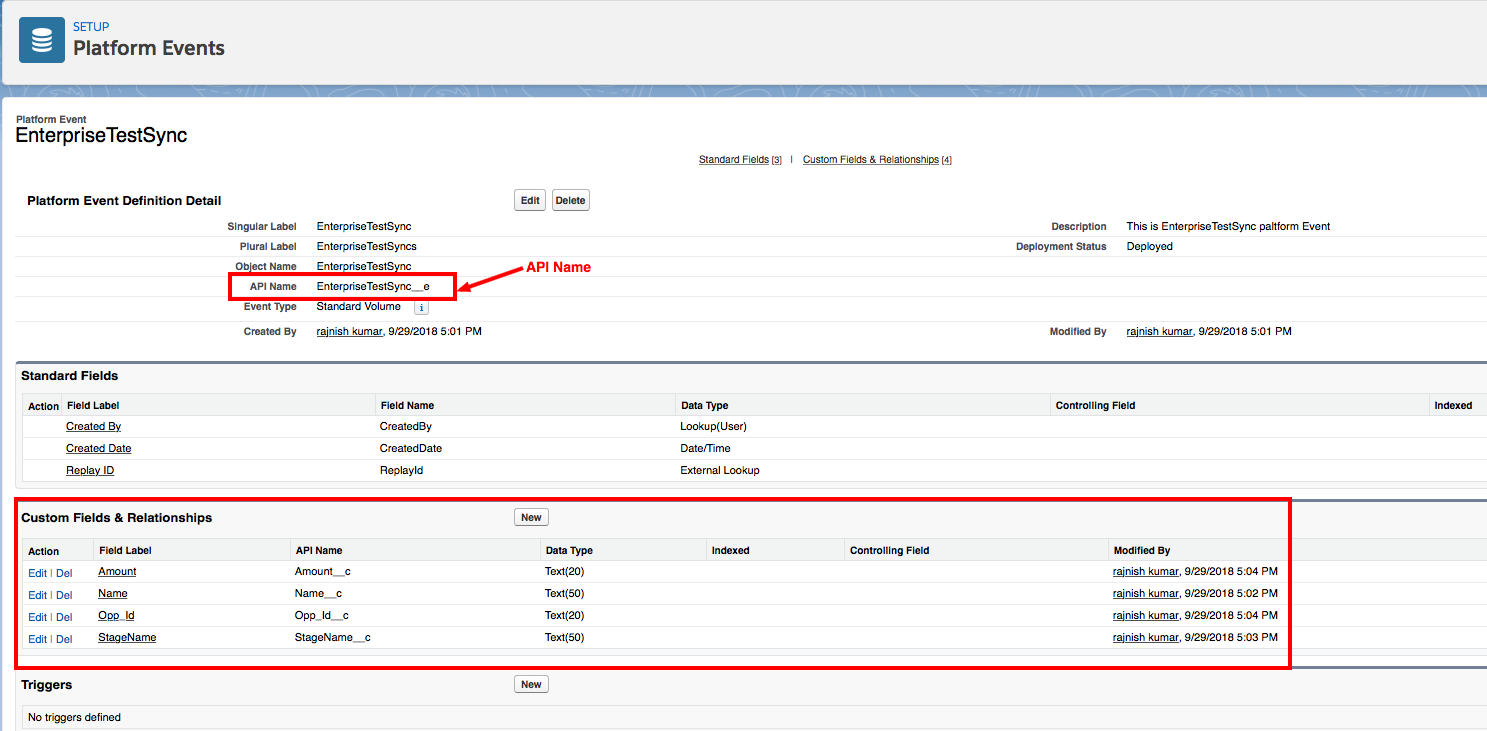
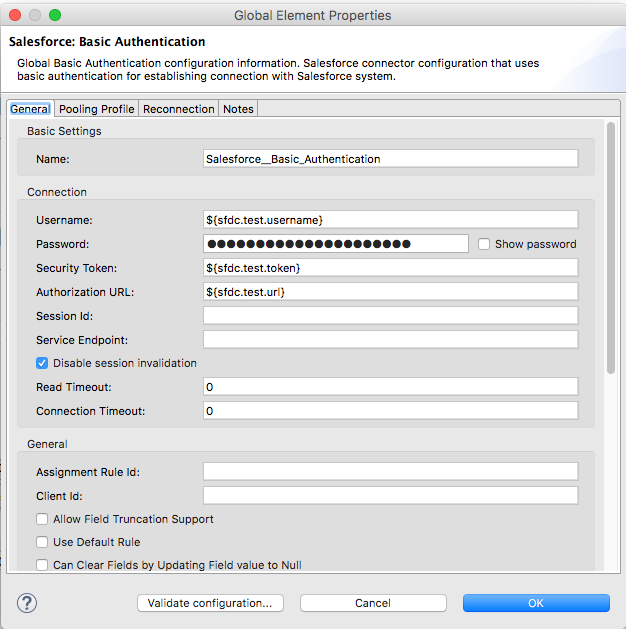
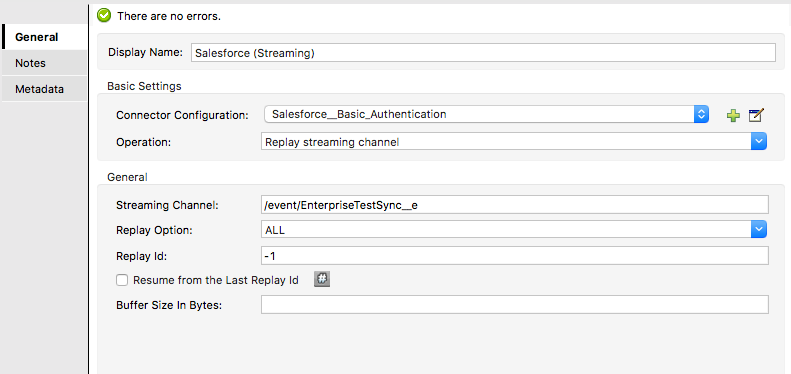
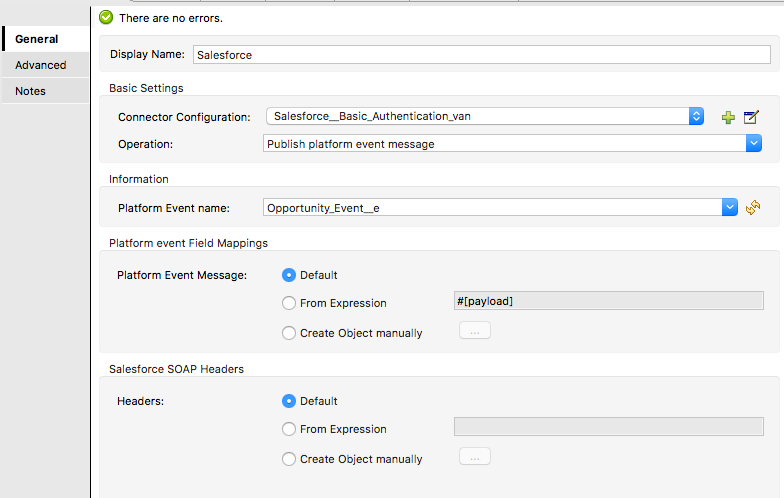
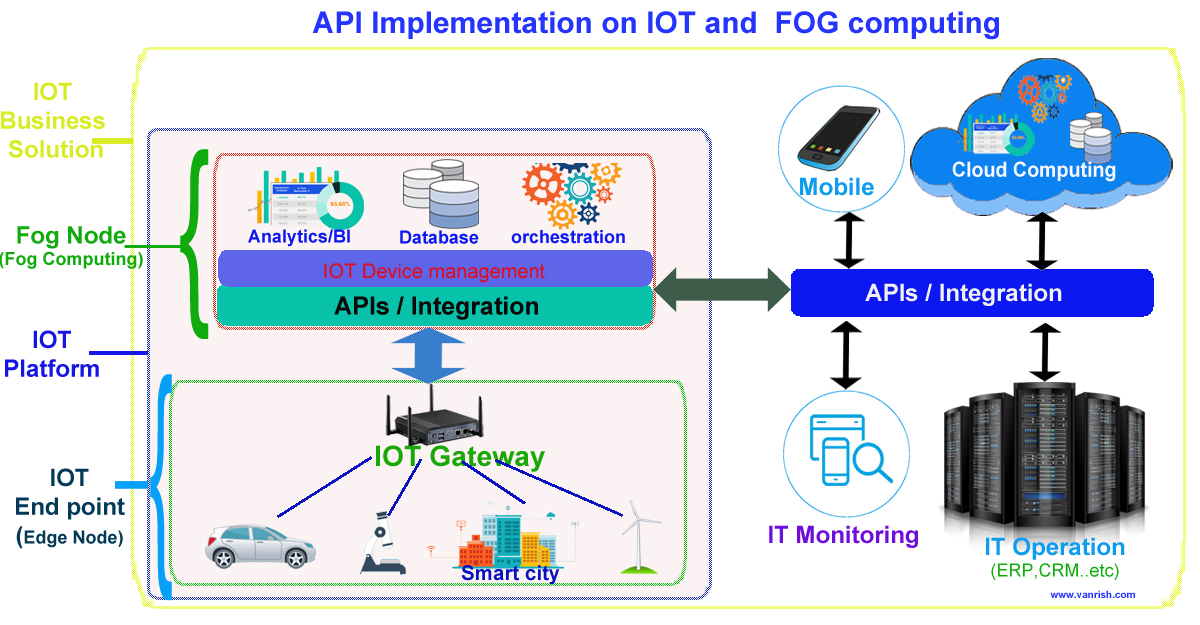
Mule 4 introduced APIKit for soap webservice. It is very similar to APIKit for Rest. In SOAP APIKit, it accepts WSDL file instead of RAML file. APIKit for SOAP generates work flow from remote WSDL file or downloaded WSDL file in your system.
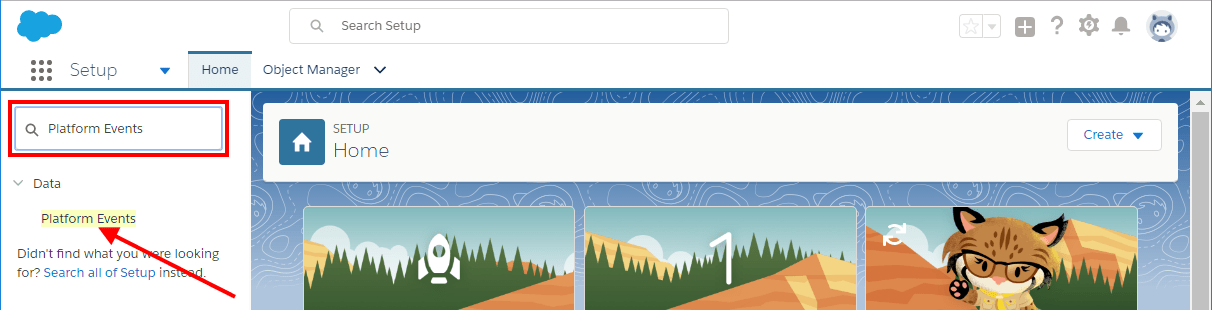
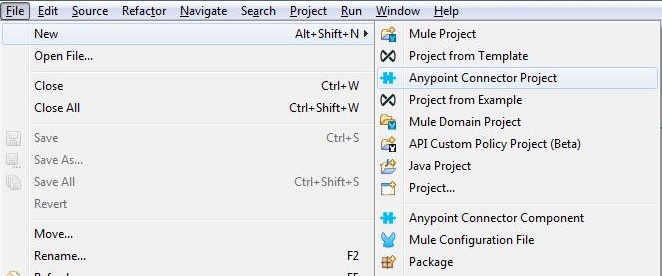
To create SOAP APIKit project, First create Mulesoft project with these steps in Anypoint studio.
Under File Menu -> select New -> Mule Project
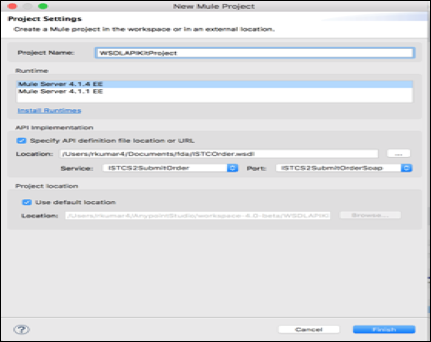
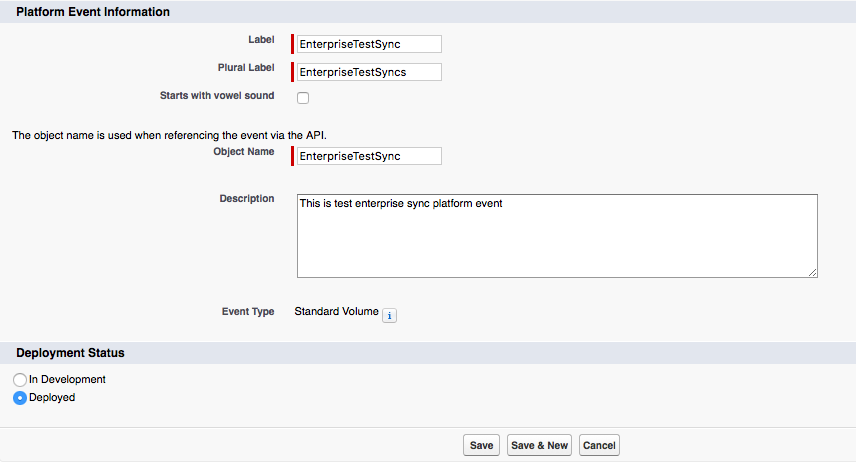
In above pic WSDL file gets selected from local folder to create Mule Project.
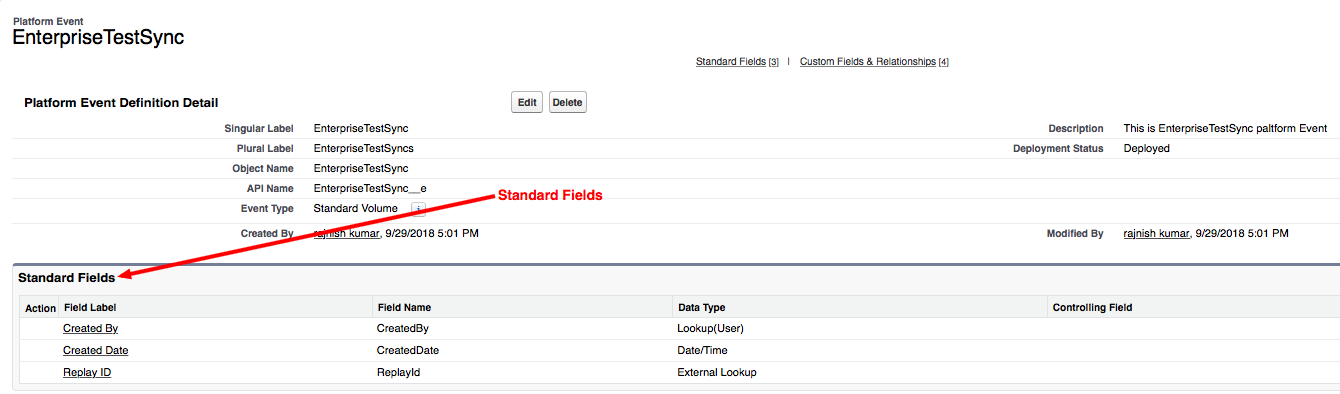
Once you click finish, it generates default APIKit flow based on WSDL file.
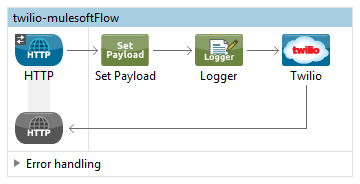
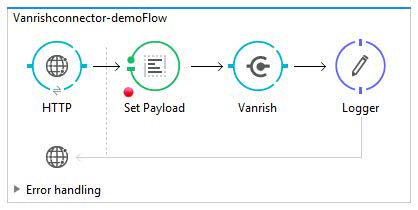
In this Mulesoft SOAP APIKit example project, application is consuming SOAP webservice and exposing WSDL and enabling SOAP webservice.
In SOAP Router APIKit, APIKit SOAP Configuration is defined WSDL location, Services and Port from WSDL file.
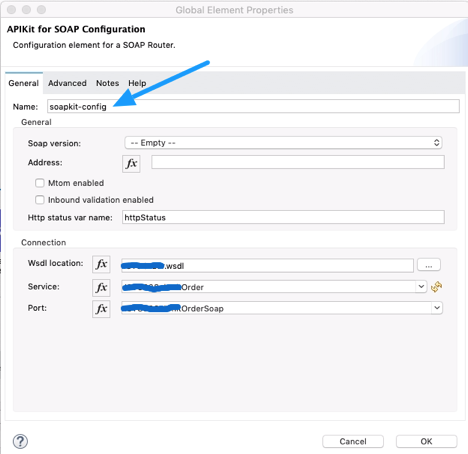
In above configuration, “soapkit-config” SOAP Router look up for requested method. Based on requested method it reroutes request from api-main flow to method flow. In this example, requested method is “ExecuteTransaction” from existing wsdl, so method flow name is
<flow name=“ExecuteTransaction:\soapkit-config”>
In this example we are consuming same WSDL but end point is different.
To call same WSDL we have to format our request based on WSDL file. In dataweave, create request based on WSDL and sending request through HTTP connector.
Here is dataweave transformation to generate request for existing WSDL file
%dw 2.0
output application/xml
ns soap http://schemas.xmlsoap.org/soap/envelope/
ns xsi http://www.w3.org/2001/XMLSchema-instance
ns ns0 http://localhost/Intellect/ExternalWebService
ns xsd http://www.w3.org/2001/XMLSchema
ns ns1 xsd:string
---
{
soap#Envelope @('xmlns:xsi': 'http://www.w3.org/2001/XMLSchema-instance'): {
soap#Body: {
ExecuteTransaction @('xmlns': 'http://localhost/Intellect/ExternalWebService'): {
Request @(xsi#'type': 'xsd:string'): payload.soap#Body.ns0#ExecuteTransaction.Request
}
}
}
}
Here is main flow

Here is full code
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<mule xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:apikit-soap="http://www.mulesoft.org/schema/mule/apikit-soap"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core"
xmlns:http="http://www.mulesoft.org/schema/mule/http"
xmlns:wsc="http://www.mulesoft.org/schema/mule/wsc"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core
http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http
http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/apikit-soap
http://www.mulesoft.org/schema/mule/apikit-soap/current/mule-apikit-soap.xsd
http://www.mulesoft.org/schema/mule/wsc
http://www.mulesoft.org/schema/mule/wsc/current/mule-wsc.xsd
http://www.mulesoft.org/schema/mule/ee/core
http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd">
<http:listener-config basePath="/fda" name="api-httpListenerConfig">
<http:listener-connection host="0.0.0.0" port="8081"/>
</http:listener-config>
<apikit-soap:config httpStatusVarName="httpStatus" name="soapkit-config" port="ISTCS2SubmitOrderSoap" service="ISTCS2SubmitOrder" wsdlLocation="ISTCOrder.wsdl"/>
<wsc:config doc:id="b2979182-c4e9-489b-9420-b9320cfe9311" doc:name="Web Service Consumer Config" name="Web_Service_Consumer_Config">
<wsc:connection address="https://enterprisetest.vanrish.com/pub/xchange/request/atlas" port="ISTCS2SubmitOrderSoap" service="ISTCS2SubmitOrder" wsdlLocation="api/ISTCOrder.wsdl"/>
</wsc:config>
<http:request-config doc:id="408de2f8-c21a-42af-bfe7-2d7e25d153b0" doc:name="HTTP Request configuration" name="HTTP_Request_configuration">
<http:request-connection host="enterprisetest.fadv.com" port="443" protocol="HTTPS"/>
</http:request-config>
<flow name="api-main">
<http:listener config-ref="api-httpListenerConfig" path="/ISTCS2SubmitOrder/ISTCS2SubmitOrderSoap">
<http:response statusCode="#[attributes.protocolHeaders.httpStatus default 200]"/>
<http:error-response statusCode="#[attributes.protocolHeaders.httpStatus default 500]">
<http:body><![CDATA[#[payload]]]></http:body>
</http:error-response>
</http:listener>
<apikit-soap:router config-ref="soapkit-config">
<apikit-soap:attributes><![CDATA[#[%dw 2.0
output application/java
---
{
headers: attributes.headers,
method: attributes.method,
queryString: attributes.queryString
}]]]></apikit-soap:attributes>
</apikit-soap:router>
</flow>
<flow name="ExecuteTransaction:\soapkit-config">
<logger doc:id="62a3748e-b81c-4a95-9af0-99c5a282b237" doc:name="Logger" level="INFO" message="Entering into flow"/>
<ee:transform doc:id="c130d7ff-bd70-4af0-b7d4-9a6caa0d771f">
<ee:message>
<ee:set-payload><![CDATA[%dw 2.0
output application/xml
ns soap http://schemas.xmlsoap.org/soap/envelope/
ns xsi http://www.w3.org/2001/XMLSchema-instance
ns ns0 http://localhost/Intellect/ExternalWebService
ns xsd http://www.w3.org/2001/XMLSchema
ns ns1 xsd:string
---
{
soap#Envelope @('xmlns:xsi': 'http://www.w3.org/2001/XMLSchema-instance'): {
soap#Body: {
ExecuteTransaction @('xmlns': 'http://localhost/Intellect/ExternalWebService'): {
Request @(xsi#'type': 'xsd:string'): payload.soap#Body.ns0#ExecuteTransaction.Request
}
}
}
}
]]></ee:set-payload>
</ee:message>
</ee:transform>
<http:request config-ref="HTTP_Request_configuration" doc:id="6d7001f3-b90a-4ed8-96d2-d577329d21d5" doc:name="Request" method="POST" path="/pub/xchange/request/atlas"/>
<logger doc:id="a05e704f-e539-48f3-9556-fe66641e3f64" doc:name="Logger" level="INFO" message="#[payload]"/>
</flow>
</mule>
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.