Fiscal year 2019, government estimated $45.8 billion on IT investments at major civilian agencies, which will be used to acquire, develop, and implement modern technologies.78% of this budget goes to maintain existing IT system. In a constantly changing IT landscape, the migration of federal on-premise technologies to the cloud is increasing every year. Federal agencies have the opportunity to save money and time by adopting innovative cloud services to meet their critical mission needs and keep up to date with current technology. Federal agencies are required by law to protect any federal information that is collected, maintained, processed, disseminated, or disposed of by cloud service offerings, in accordance with FedRAMP requirements.
What is Federal Risk and Authorization Management Program (FedRamp) ?
FedRamp is a US government-wide program that delivers a standard approach to security assessment, authorization, and continuous monitoring for cloud products and services. The stakeholders for FedRamps are
Federal Agencies
FedRamp PMO & JAB(Joint Authorization Board)
Third Party Assessment Organization
FedRamp Process— There are 3 ways a cloud service can be proposed for FedRamp Authorization.
Cloud BPA — Cloud Services through FCCI BPAs
Government Cloud Systems — Services must be intended for use by multiple government or government approved agencies.
Agency Sponsorship — This is the most popular route for cloud service providers (CSPs) to take when working toward a FedRAMP Authorization. CSP to establish a partnership with an Agency and agree to work together for an Authority to Operate(ATO).
Mulesoft FedRAMP Authorize Integration Platform
Mulesoft recently announced, FedRAMP process implementation of Anypoint Platform. MuleSoft is one of the first integration platform companies with FedRamp authorization and enabling both on-premises and cloud integration in the federal government and state government. Enablement of FedRamp of Mulesoft Anypoint platform, government IT teams can leverage the same core Anypoint Platform benefits in the cloud to accelerate their project delivery via reusable APIs.Anypoint Platform allows all government integration assets to be managed and monitored from a single, secure, cloud based management console, simplifying operations and increasing IT agility.
Mulesoft Anypoint platform enables FedRamp-compliant iPAAS for government organization. Government IT integration project deploy in Anypoint platform within Mulesoft Government cloud
Accelerate government IT project deliveries by deploying sophisticated cross-cloud integration applications and create new APIs on top of existing data sources
Project deliveries improve efficiencies at lower cost by allowing IT integration teams to focus on designing, deploying, and managing integrations in the cloud and allowing agencies to only pay for what they use, .
Reduce risk of your IT project integration and increase application reliability by using of self-healing mechanism to recover from problems and load balancing.
What is Mulesoft Government Cloud?
Mulesoft government cloud is a FedRamp-compliant, cloud based deployment environment for Anypoint platform.
It is built on AWS GovCloud with FedRamp control.
Mule Runtimes configured in secure mode to support the highest encryption standards and FIPS(Federal Information Processing Standard) 140-2 hardware and software encryption compliance.
It is FedRamp-compliance at the moderate impact level.
It is continuous 3rd party(3 POs) auditing and monitoring of security control.
If you are accessing FedRamp-compliant Anypoint platform, after logging you get end user agreement as a consent. It is very typical for FedRamp-compliant government application.
Conclusion — Executing any government or state project and working on different integration as well as API enablement, FedRamp-compliant Anypoint platform is one of the best options. It accelerate IT project deliveries, improve efficiencies and reduce IT risk .
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Mulesoft is all about API strategy and digital transformation of your organization through APIs within cloudHub or in premise. Mulesoft also provides platform for APIs to monitor and analyze the usage, control access and protect sensitive data with security policies. API is at the heart of digital transformation and it enables greater speed, flexibility and agility of any organization.
Exposing of your APIs is one aspect of your digital transformation strategy, but consuming API is also as important as exposing APIs. Consuming API is either application getting data from APIs or create/update data through APIs. Most of APIs are based on HTTP/HTTPS protocol. In Mule 4 consuming APIs is also start with configuration of HTTP/HTTPs protocol.
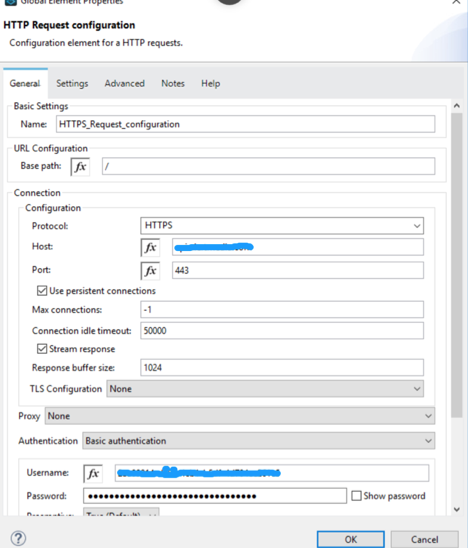
Configuration of HTTP/HTTPS— HTTP/HTTPS configuration start with selecting protocol. If API is available through HTTP then select protocol HTTP with default port 80 or change port based on expose API document. If APIs are available through secured connection, then select HTTPS protocol with default port 443. Fill the Host with your expose API end point without any protocol. Fill the other field with default value.
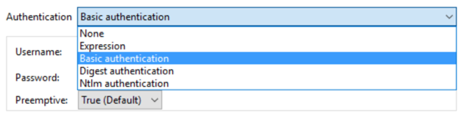
Authentication of API are available with five different selection
None – No authentication. Available
for everyone
Expression – Custom or expression-based
authentication
Digest authentication — web server
can use to negotiate credentials, such as username or password, with a user’s
web browser
Ntlm authentication — NT (New
Technology) LAN Manager (NTLM) . Microsoft security protocols intended to
provide authentication, integrity, and confidentiality to users
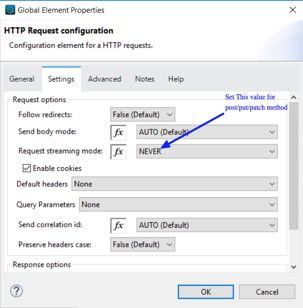
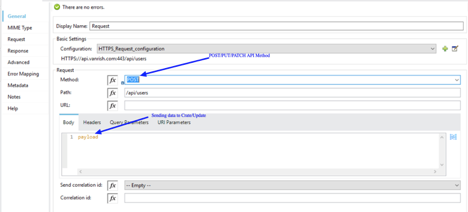
If you are working on post/patch/put method api to send data into expose api, set some important parameter based on streaming mode. If API are exposed as streaming mode, then you need to mention content-size of streaming otherwise set value as “NEVER”, then you no need to set content-size.
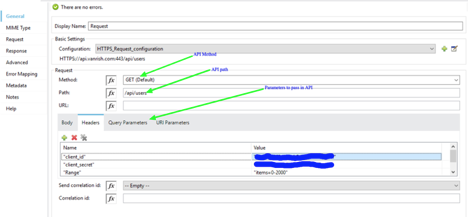
API Get Call – API get call implement GET method of APIs. Implementation of API get call need parameters. Based on these parameters application get set of data. MuleSoft provide 4 ways to pass these parameters or values.
Body
Headers
Query Parameters
URI Parameters
Flow for GET Method
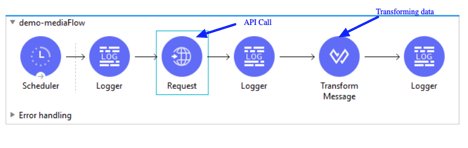
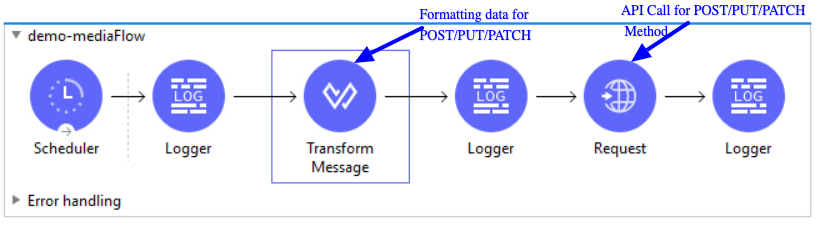
API POST/PUT/PATCH Call –
POST – Create data
PUT/PATCH – Update data
Similar to Get method call, for POST/PUT/PATCH method application send API parameters based on API requirement. Since application is creating/Updating data through POST/PUT/PATCH api call, application sends these data through body parameters with content-type.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Mule 4 introduced APIKit for soap webservice. It is very similar to APIKit for Rest. In SOAP APIKit, it accepts WSDL file instead of RAML file. APIKit for SOAP generates work flow from remote WSDL file or downloaded WSDL file in your system.
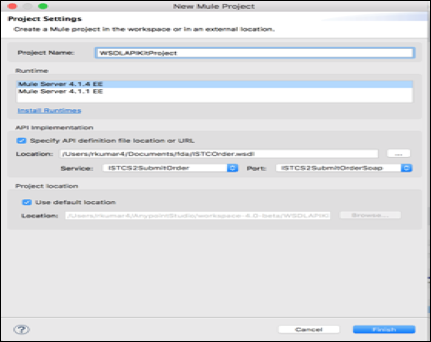
To create SOAP APIKit project, First create Mulesoft project with these steps in Anypoint studio.
Under File Menu -> select New -> Mule Project
Mule 4 Project Settings
In above pic WSDL file gets selected from local folder to create Mule Project.
Once you click finish, it generates default APIKit flow based on WSDL file.
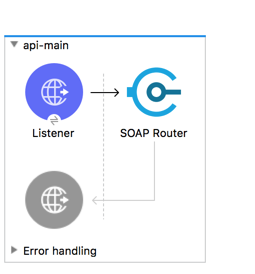
In this Mulesoft SOAP APIKit example project, application is consuming SOAP webservice and exposing WSDL and enabling SOAP webservice.
Mule 4 API Kit for Soap Router
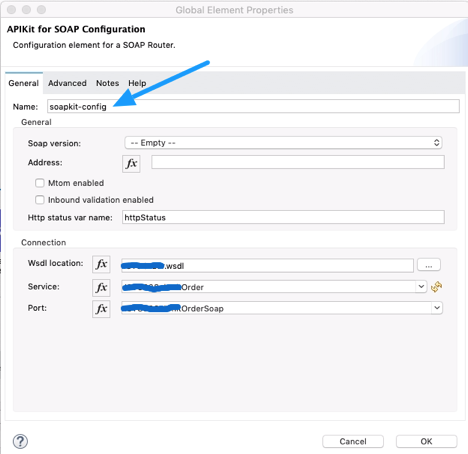
In SOAP Router APIKit, APIKit SOAP Configuration is defined WSDL location, Services and Port from WSDL file.
API Kit SOAP configuration
In above configuration, “soapkit-config” SOAP Router look up for requested method. Based on requested method it reroutes request from api-main flow to method flow. In this example, requested method is “ExecuteTransaction” from existing wsdl, so method flow name is
<flow name=“ExecuteTransaction:\soapkit-config”>
In this example we are consuming same WSDL but end point is different.
To call same WSDL we have to format our request based on WSDL file. In dataweave, create request based on WSDL and sending request through HTTP connector.
Here is dataweave transformation to generate request for existing WSDL file
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
When I started my career, there was Y2K issue going on. Every company was trying to convert
their data to be compatible with
upcoming Y2K. In that era, all companies without any 2nd thought
were allocating their budgets in these projects. They wanted to make their systems compatible to Y2K as soon as possible.
Currently
companies are going through same situation. This time it is Digital transformation. All industries
want to enable digital transformation to expand their business. Digital transformation
is touching every company in every industry. But CEOs and CTOs have big
challenge to enable data for business and drive their company towards digital
transformation.
Suppose
you are in supply chain industries and your data is sitting in some legacy
system. So in this case there is no use
of data. Business will not be able to
run any analytic on this data so that business can identify customer behavior
or new business opportunity. It will not be able to add any business value with
this data. Company can go out of business due to this lack of vision and data
transformation. In this fast pace world,
keeping relevant to your customer it is very necessary to your business to move
your data fast and enable new business opportunity.
Here are few challenges CTO’s/Architect are facing to enable
their data transformation and delivering innovation.
All systems are not delivering seamless
experience within organization. Every department is working independently.
There is Lack of support for 360 degree view of
customer or an agent from the various touch points of business.
Duplicate data between systems and lack of data
transparency.
Growing need of security and compliances are not
implemented with growing business.
Here are some of steps to achieve your company’s digital
transformation vision.
1. Establish digital vision – If you are leading your company towards digital transformation, it is very necessary that you have very clear vision and strategy around your business requirement. Give training to all stakeholder to embrace new changes due to digital transformation. Engage business leadership in developing a business capability roadmap.
2. Seamless experiences –
Establish seamless experience via user experience design, mobile, agent, customer
and service center. Interface need to be fast and provide self service
capability. Enable single source of information available system-wide through
the API-based integration layer.
3. 360 degree customer
view – Setup some process to get a complete view of customers by
aggregating data from the various touch points that a customer may use to
contact a company to purchase products and receive service and support. Data
assets are buried in the data center. APIs bring these data in front of
the people who need it to drive new products and new digital services for
customers and provide 360 degree view of this data.
4. Embrace
the Cloud – Cloud is providing a platform to accelerate company digital transformation
journey.Companies are innovating very
fast in cloud. They are taking advantage of lower coast and fast deliverable of
cloud without worry about IT infrastructure. They are moving data and enable
data for artificial Intelligence and analytics through less roll out time of
cloud.
Conclusion – Better
digital transformation strategy brings better workspace and increase in stakeholder
involvement. It increase productivity and bring more innovation for your
business.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Much awaited Mulesoft 4 was officially announced in Mulesoft
Connect 2018 in San Jose. When Mulesoft was born, it was really to create
software that helps to interact systems or source of information quickly within
or outside company. So the speed is an incredibly important thing over the
years to develop and interact within systems. Need of speed for application and
development hasn’t change drastically over the years but needs and requirement
of customer’s application have changed. The integration landscape has also
magnified. There are hundreds of new systems and sources of information to
connect to, with more and more integration requirements. This integration
landscape gets very messy and very quickly.
Mule 4 provides
a simplified language, simplified runtime engine and ultimately reduces
management complexity. It helps
customers, developers to deliver application faster. Mule4 is really radically
simplified development. It is providing new tool to simplify your development,
deployment and management of your integration/API. It is also providing a
platform to reuse Mule component without affecting existing application for
faster development. Mule 4 is evolution of Mule3. You will not seem lost in
Mule 4, if you are coming from Mule3. But Mule 4 implements fewer concepts and
steps to simplify whole development/integration process. Mule 4 has now java
skill is optional. In this release Mulesoft is improving tool and making error
reporting more robust and platform independent.
Now let’s go one by one with all these new Mule4 features.
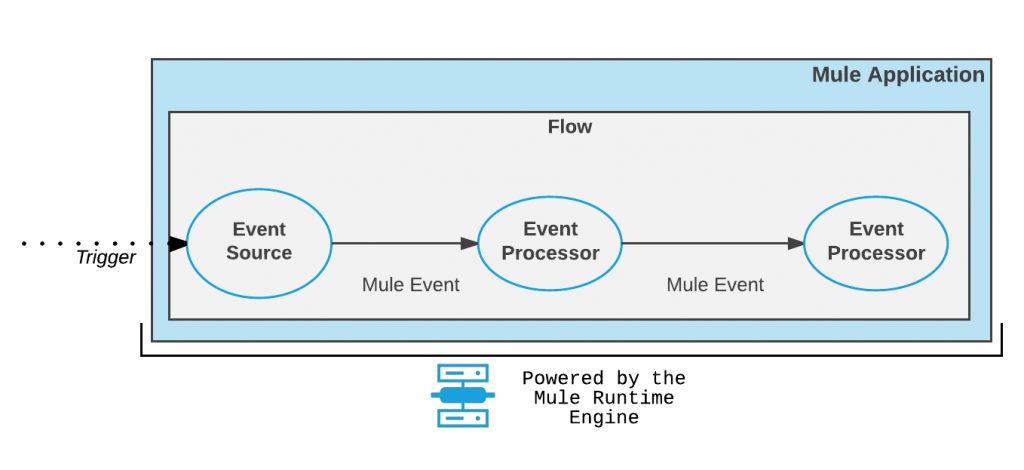
1. Simplified
Event Processing and Messaging — Mule event is
immutable, so every change to an instance of a Mule event results in the
creation of a new instance.It contains the core
information processed by the runtime. It travels through components inside your
Mule app following the configured application logic. A Mule event is generated when a trigger (such as an
HTTP request or a change to a database or file) reaches the Event source of a
flow. This trigger could be an external event triggered by a resource that
might be external to the Mule app.
Mule 4 Event flow
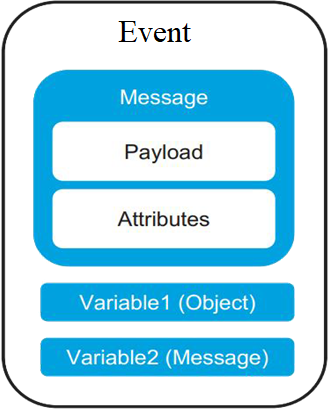
2. New
Event and Message structure — Mule 4 includes a
simplified Mule message model in which each Mule event has a message and
variables associated with it. A Mule message is
composed of a payload and its attributes (metadata, such as file size).
Variables hold arbitrary user information such as operation results, auxiliary
values, and so on.
Mule 4 message
Mules 4 do not have Inbound, Outbound and Attachment
properties like Mule 3. In mule 4 all information
are saved in variables and attributes. Attributes in Mule 4 replace inbound properties. Attributes
can be easily accessed through expressions.
These
are advantages to use Attributes in
Mule 4.
They are strongly typed, so you can easily see
what data is available.
They can easily be stored in variables that you
can access throughout your flow
Example :
#[attributes.uriParams.jobnumber]
Outbound properties— Mule 4 has no concept for outbound properties like in Mule 3. So you can set status code response or header information in Mule 4 through Dataweave expression without introducing any side effects in the main flow.
Session Properties–In Mule 4 Session properties are no longer exist. Data store in variables are passes along with different flow.
3. Seamless data access & streaming – Mule 4 has fewer concepts and steps. Now every steps and task of java language knowledge is optional.Mule 4 is not only leveraging DataWeave as a transformation language, but expression language as well. For example in Mule 3 XML/CSV data need to be converted into java object to parse or reroute them. Mule 4 gives the ability to parse or reroute through Dataweave expression without converting into java. These steps simplify your implementation without using java.
Mule 4 Data Access
4. Dataweave 2.0 — Mule 4 introduces DataWeave as the default
expression language replacing Mule Expression Language (MEL) with a scripting
and transformation engine. It is combined with the built-in streaming
capabilities; this change simplifies many common tasks. Mule 4
simplifies data iteration. DataWeave knows how to iterate a json array. You
don’t even need to specify it is json. No need to use <json:json-to-object-transformer /> to convert data into java object.
Mule 4 vs Mule 3 flow comparison
Here are few points about Dataweave 2.0
Simpler syntax to learn
Human readable descriptions of all data types
Applies complex routing/filter rules.
Easy access to payload data without the need for
transformation.
Performs any kind of data transformation,
normalization, grouping, joins, pivoting and filtering.
5. Repeatable
Streaming – Mule 4 introduces
repeatable streams as its default framework for handling streams. To understand
the changes introduced in Mule 4, it is necessary to understand how Mule3 data
streams are consumed
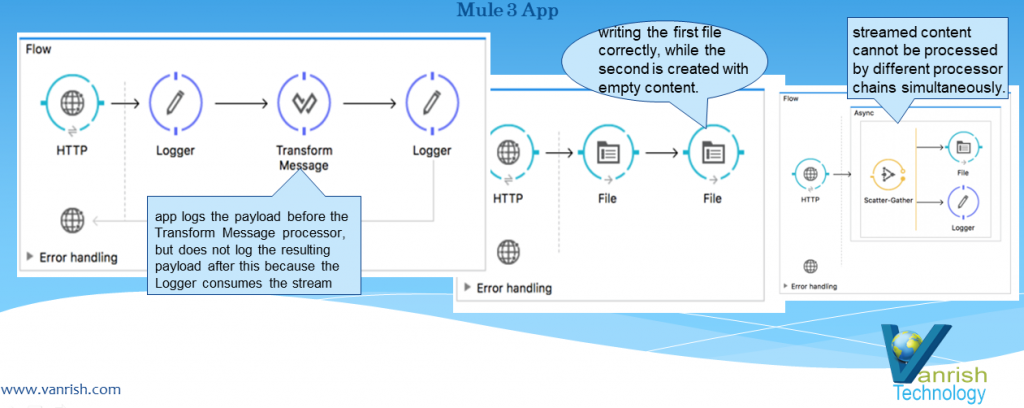
Mule 3 data streaming examples
In above three different Mule 3 flows, once stream data is
consumed by one node it is empty stream for 2nd node. So in the above
first example, in order to log the stream payload , the logger has to consume
the entire stream of data from HTTP connector. This means that the full content
will be loaded into memory. So if the content is too big and you’re loading
into memory, there is a good chance the application might run out of memory.
So Mule 4 repeatable streams enable you to
Read a stream more than once
Have concurrent access to the stream.
Random Access
Streams of bytes or streams of objects
As a component consumes the stream, Mule saves its content
into a temporary buffer. The runtime then feeds the component from the
temporary buffer, ensuring that each component receives the full stream,
regardless of how much of the stream was already consumed by any prior
component
Here are few points, how repeatable streams works in Mule 4
Payload
is read into memory as it is consumed
If
payload stream buffer size is > 512K (default) then it will be persisted to
disk.
Payload
stream buffer size can be increased or decreased by configuration to optimize
performance
Any
stream can be read at any random position, by any random thread concurrently
6. Error Handling — In Mule 4 error handling has been changed
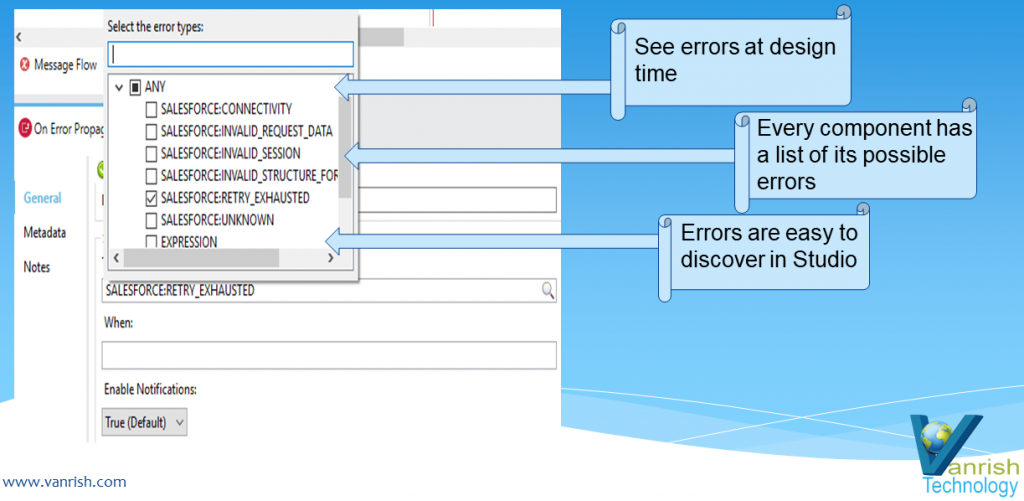
significantly. Now In mule 4 you can discover errors at design time with visual
interface. You no need to deal with java exception directly and it is easy to
discover error while you are building flow. Every flow listed all possible
exception which potential arises during execution.
Mule 4 Error Handling
Now errors that occur
in Mule fall into two categories
Messaging errors
System errors
Messaging errors — Mule throws a messaging error (a Mule error) whenever a problem occurs within a flow. To handle Mule
errors, you can set up On Error components inside the scope-like Error Handler
component. By default, any unhandled errors are logged and propagated.
System errors — Mule throws a system error when an exception occurs
at the system level . If no Mule Event is involved, the errors are handled by a
system error handler.
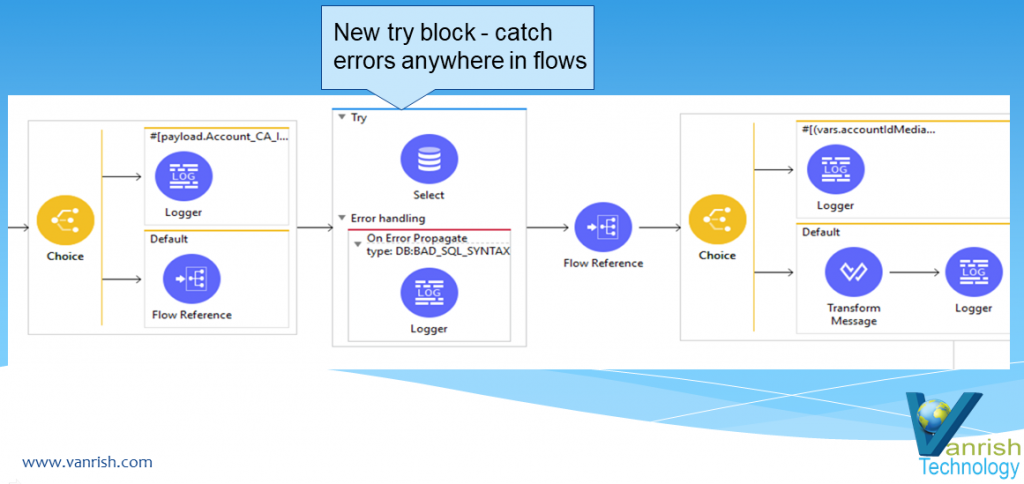
Try catch Scope — Mule 4 introduces a new try scope that you can use within a flow to do error handling of just inner components/connectors. This try scope also supports transactions and in this way it is replacing Old Mule 3 transaction scope.
Mule 4 A new try catch block
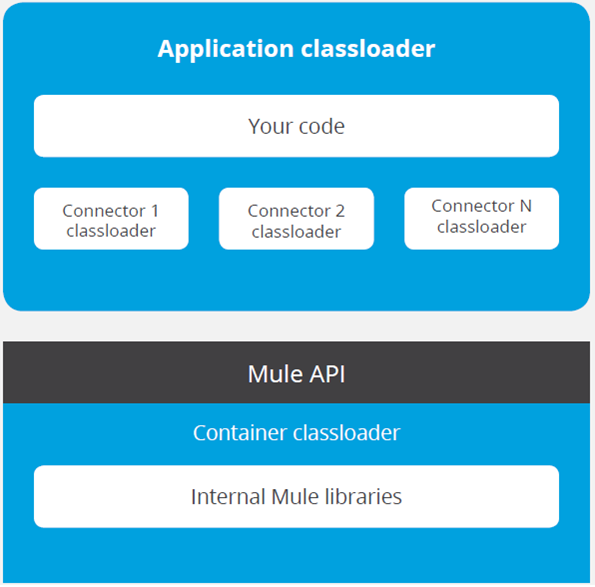
7. Class Loader Isolation — Class loader separates application completely from
Mule runtime and connector runtime. So, library file changes (jar version) do
not affect your application. This also
gives flexibility to your application to run any Spring version without worry
about Mulesoft spring version. Connectors are distributed outside the runtime
as well, making it possible to get connector enhancements and fixes without
having to upgrade the runtime or vice versa
In above pic showing that every component in any application have their own class loader and running independently on own class loader.
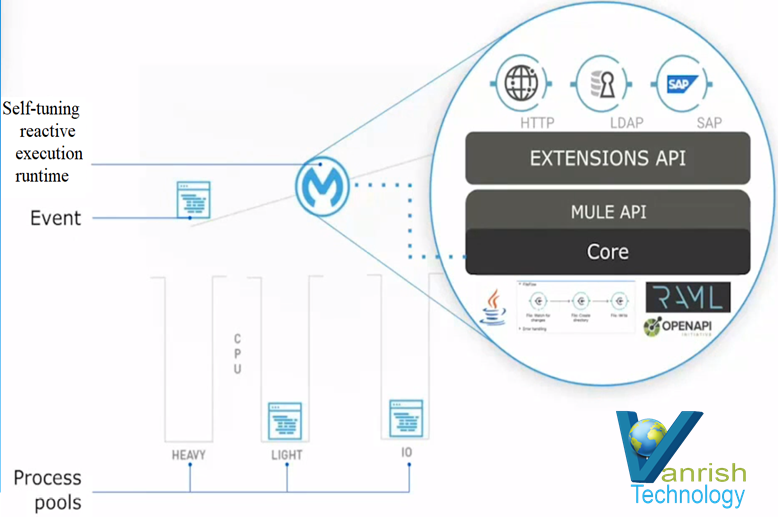
8. Runtime Engine — Mule 4 engine is new reactive and non-blocking engine. In Mule 4 non-blocking flow always on, so no processing strategy in flow. One best feature of Mule 4 engine is, It is self-tuning runtime engine. So what does this mean? If Mule 4 engine is processing your applications on 3 different thread pools, So runtime knows which application should be executed by each thread pool. So operation put in corresponding thread pool based on high intensive CPU processing or light intensive CPU processing or I/O operation. Then 3 pools are dynamic resizing automatically to execute application through self-tuning.
Mule 4 : Self tuning run time engine
So now self-tuning creates custom thread pools based on specific tasks. Mule 4 engine makes it possible to achieve optimal performance without having to do manual tuning steps.
Conclusion
Overall Mule 4 is
trying to make application development easy, fast and robust. There are more features
included in Mule 4 which I will try to cover in my next blog. I will also try
to cover more in depth info in above topic of Mule 4. Please keep tuning for my
next blog.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Summer 2017 Salesforce released new event-driven architect “Platform Events” feature. Salesforce is known for its custom metadata platform, and now it is delivering a custom messaging platform, so Salesforce customers can build and publish their own events. Platform Events enables customer to increase business productivity and efficiency through integration via event. This feature reduces point-to-point integration and expands the existing capability with more integration options like Outbound Messaging, Apex Callouts, and the Streaming API. With platform events, there are two parties to the communication: a sender and a receiver. They are two of the components of an event-driven architecture.
Before going any further, let’s define some of terminology of platform event.
Event — A change in state that is meaningful in a business process. For example, if opportunities are created or updated in salesforce, this action will generate event within salesforce.
Event message – An event message is payload of event. For example, events are generated after creating or updating opportunities. So, this event has all updated data or updated delta of data which comes as payload.
Event producer – Publishing event with event message is event producer. For example, publish opportunities payload after generating event for other system.
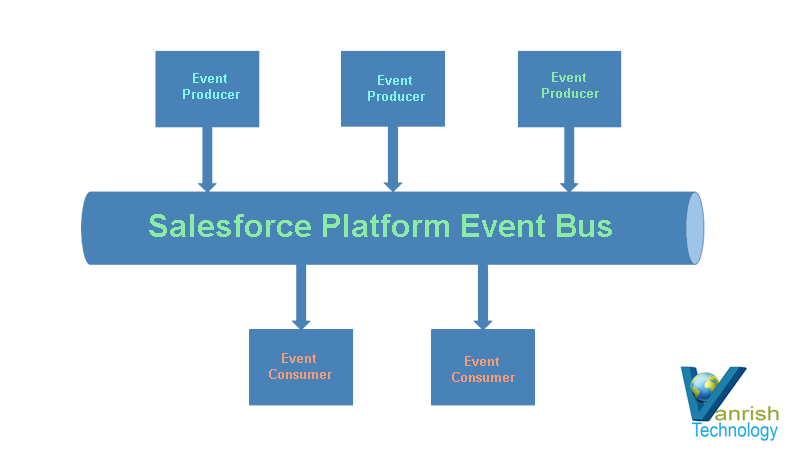
Event channel — A stream of events on which an event producer sends event messages and event consumers read those messages.
Event consumer — A subscriber/Event consumer is an event channel that receives messages from the Event Bus. For example, Application which is subscribing event channel to process further is event consumer.
Event-based software architecture
Set Up Platform Events in Salesforce
On the Salesforce page, click the Setup icon in the top-right navigation menu and select Setup.
Salesforce setup link
Enter Platform Events into the Quick Find box and then select Data > Platform Events.
Salesforce platform event link
Click New Platform Event.
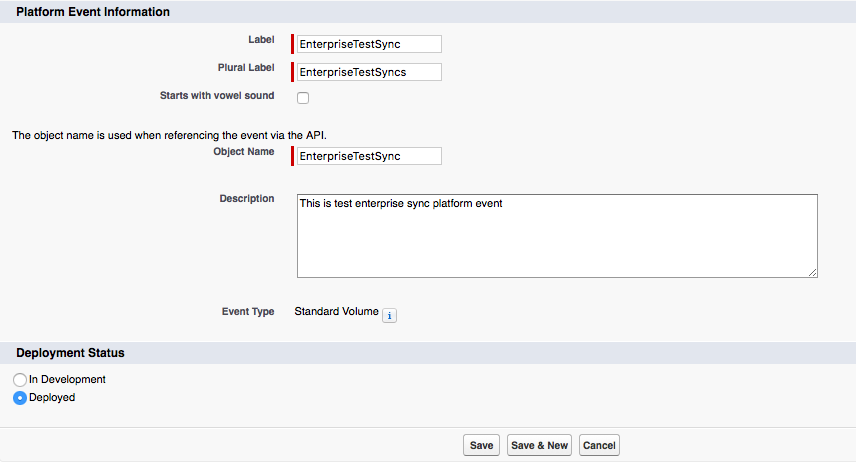
In the New Platform Event form, please fill all form
Field Label: EnterpriseTestSync
Plural Label: EnterpriseTestSyncs
Object Name: EnterpriseTestSync
Salesforce platform event configuration
Click Save
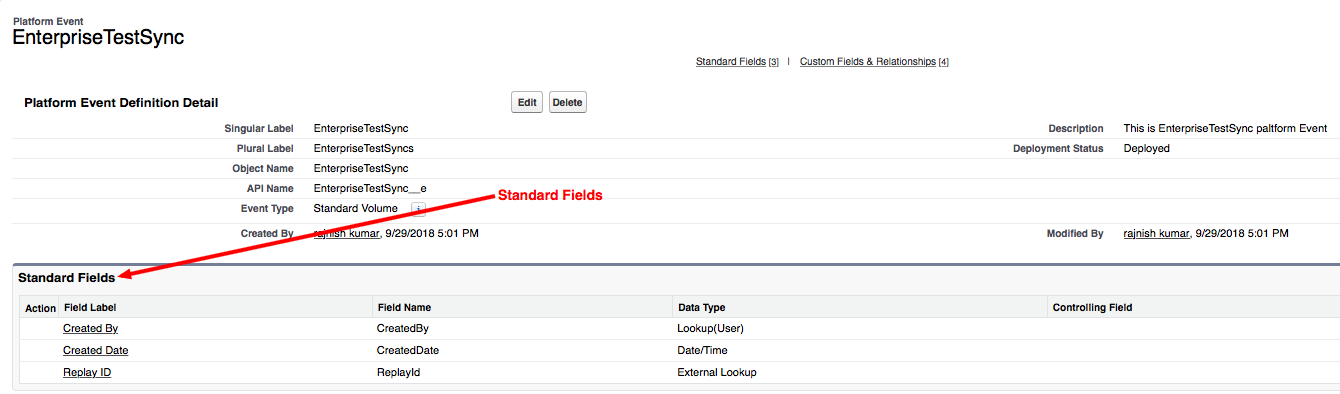
It will be redirected to the EnterpriseTestSync Platform Event page. By default, it creates some standard fields.
Salesforce platform event standard fields
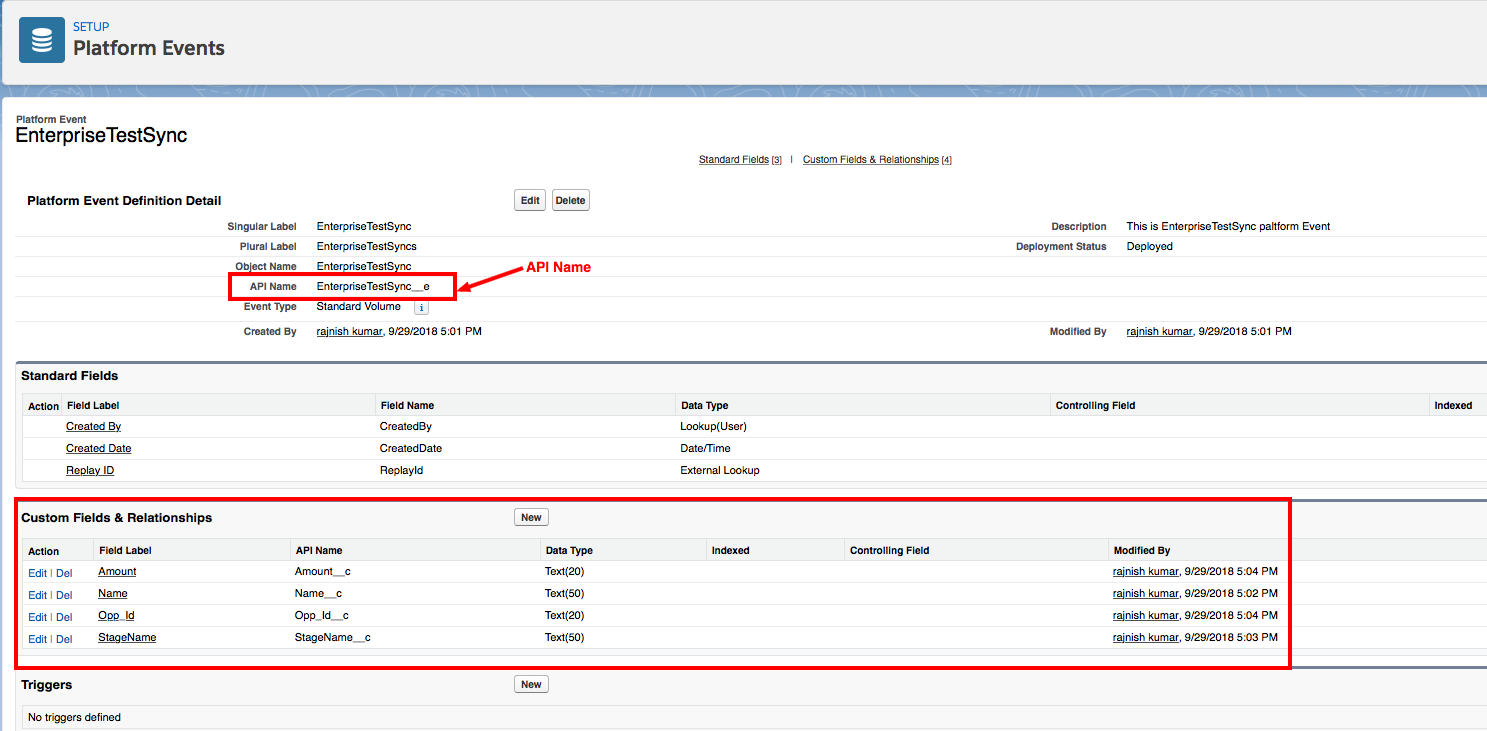
Now you need to create Custom Platform Event fields that correspond to your EnterpriseTestSync. In the Custom Fields & Relationships section, click New to create a field for EnterpriseTestSync.
Make sure that the Enterprise Test Sync API Name is EnterpriseTestSync__e and that Custom Fields & Relationships looks like this.
Salesforce platform event API name
If you have any trigger for platform event you can create in trigger section.
Click Save.
Save action will create platform event in salesforce. In next section create Mulesoft integration flow
Integration Mulesoft and Plateform Event
To Integrate with Salesforce Platform Events, please download Mulesoft Salesforce connector v8.4.0 or beyond from Anypoint Exchange.
In my example, I am creating application which syncs salesforce opportunity between two salesforce instances. So, any create or update opportunity will create platform event in salesforce instance. This platform event is subscribed by Mulesoft Salesforce platform event connector in first salesforce instance. Mulesoft receives platform event and platform message from first salesforce instance. Mulesoft transforms this platform message into another format of message and publishes into other salesforce platform event. Platform event can be tracked by replay id. Replay id is unique field when Salesforce generates any platform event. Platform event message persist only 24 hrs in platform Event Bus. We can replay this message within 24hrs.
Here are the steps for Mulesoft integration with Salesforce platform event and flow to communicate between two Salesforce platform event.
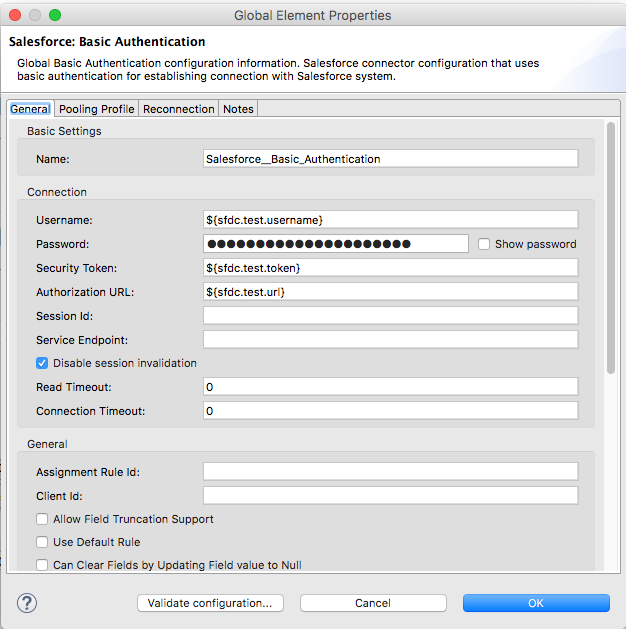
Please configure Salesforce Basic Authentication from global element in Anypoint studio.
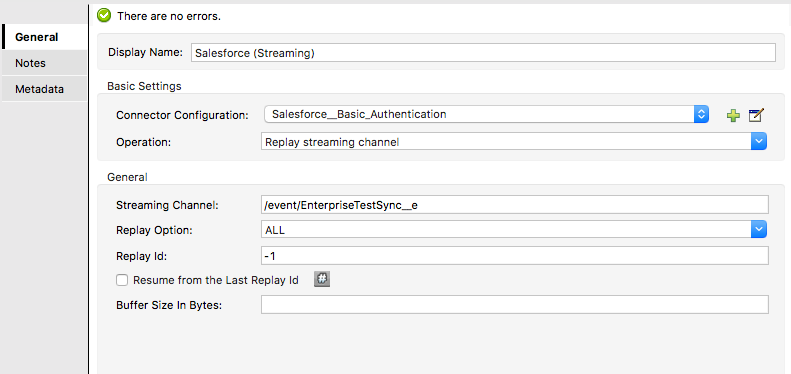
Configure Salesforce connector for platform event which listen Salesforce platform event from event channel.
Select operation as “Replay streaming channel”
Streaming Channel: Add “/event/EnterpriseTestSync__e”. “EnterpriseTestSync__e” is API name from Salesforce platform event. This API listen event with /event/
Replay option: There are 3 options
ALL – This option replays all message from event channel
FROM_REPLAY_ID – This option replays only specific event message replay Id
ONLY_NEW – This option replay only new event messages from channel.
Replay Id: Replay option ALL we pass -1 value. For FROM_REPLAY_ID option we pass specific event message replay Id and for ONLY_NEW we pass -1
Check box “Resume from the Last Replay Id” resume from last replay Id and ignore rest.
Once it is configured, it is ready to accept event message from platform event Channel. Add transformation logic to publish platform event into other Salesforce instances.
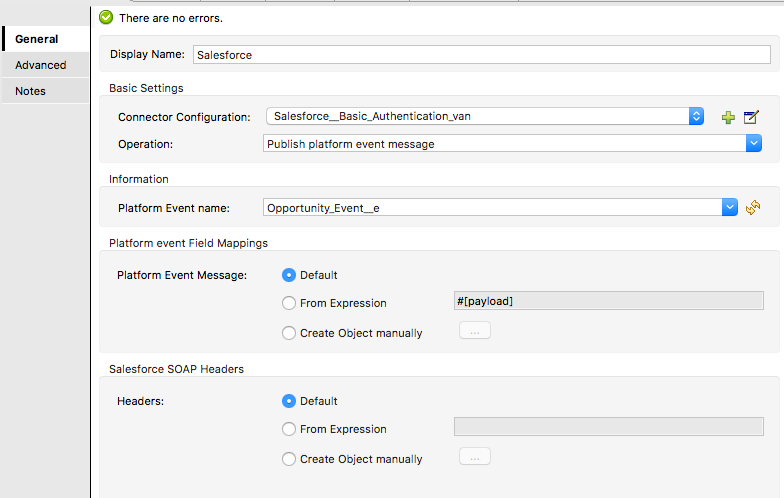
Configure Salesforce platform event for publish event message into
Once you configure these ends point application is ready to listen Event from first instance of Salesforce Platform event and publish platform event into other instance of Salesforce.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
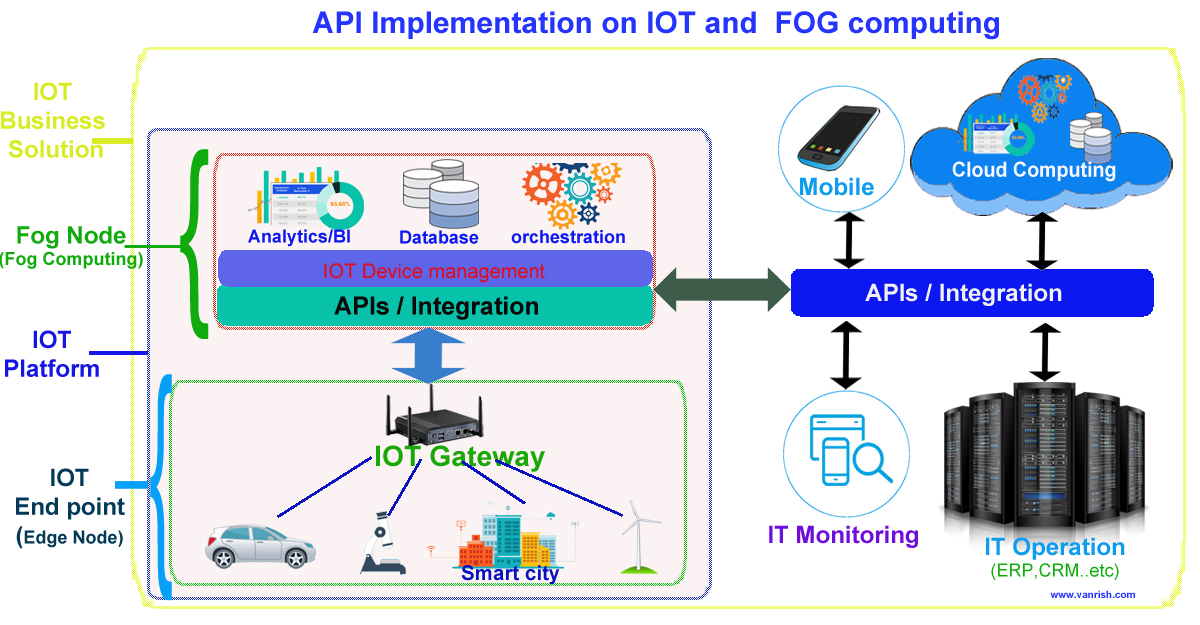
IOT (Internet Of Things) is transforming whole business and bringing new revolution in all kinds of business. These IOT devices generating terabytes of data. To handle unprecedented volume, variety and velocity of data, IOT needs new kind of infrastructure to support whole IOT eco system. FOG computing is a part of IOT eco system to support large volume of data with quick response. I explained in my previous blog, how FOG computing is now becoming major role in IOT devices. FOG is intermediate platform to collaborate between Cloud computing and Edge computing(IOT) to transfer data. Fog can hold small number of data and less computing power. Large data is stored in cloud and heavy computing is done in Cloud.
API (Application Programming Interface) have major role to transfer data from edge device (IOT) to Fog node and from fog node to Cloud (Internet). API is helping to collaborate between edge device to Fog node and Fog node to Cloud. API is playing major role to maintain volume, variety and velocity of data in IOT infrastructure.
API works on HTTP/HTTPS protocol. APIs are light weight and simple. Enabling APIs take very small amount of resource. So, API can enable in small system and consume without losing too much resources. This API property helps to transfer data from Edge device(IOT) to Fog node and from Fog node to Cloud. API is not part of mechanical role. API is responsible for the optimization of data transfer. Proper enabling of APIs between these nodes increase the efficiency and computational power to all IOT devices. Fog node is intermediate node between IOT device and cloud. So, Fog node will be responsible to receive data from edge(IOT) device and transfer these data to Cloud. Communication between Edge(IOT) device to Fog node is very frequent. Data provided by API is responsible for all intermediate and quick computation on FOG node.
Cloud is still big stake holder for holding all data and large computation from IOT device. API is providing data to cloud from FOG node in certain interval for heavy computation. As Edge(IOT) system getting more complex Fog computation responsibility will increase and API will come on picture to provide more data to Fog and from fog node to cloud.
API Integration of IOT with Fog and Cloud computing.
These are few benefits by enabling APIs for IOT devices and Fog Nodes
API provides flexibility to connect any IOT device to FOG node and FOG node to cloud network.
API provides seamless connectivity between these systems.
API brings whole IOT system in one seamless environment So, it is very easy to debug these systems.
API is very easy to develop and deploy so it’s easy to maintain these systems.
Provisioning of IOT device has also become very easy by enabling API.
According to Gartner study, Security of IOT is one of big concern. API provides whole one seamless system and network to mitigate this risk.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
IOT, Connect car, Automated car getting lot of traction in current word. All big companies want to be part of this process. All kind of sensors are installed in these vehicles. These sensors generate Terabytes of data and computing these data to run vehicle smoothly. Connected car or IOT based devices are completely based on computing power and quick response.
Sending data and computing these data in cloud could be catastrophic. Any network latency and processing delay might end with bad result. For example, your automated car is traversing through busy street. Suddenly a person comes in front of automated car. In this scenario, any network latency, slowness of computation and analysis effects the decision and subsequent action (Apply brake on car).
In IOT based device, any computing near to IOT device can reduce this risk. So how can we make this happen, if your all computing power are in cloud and data is in cloud.
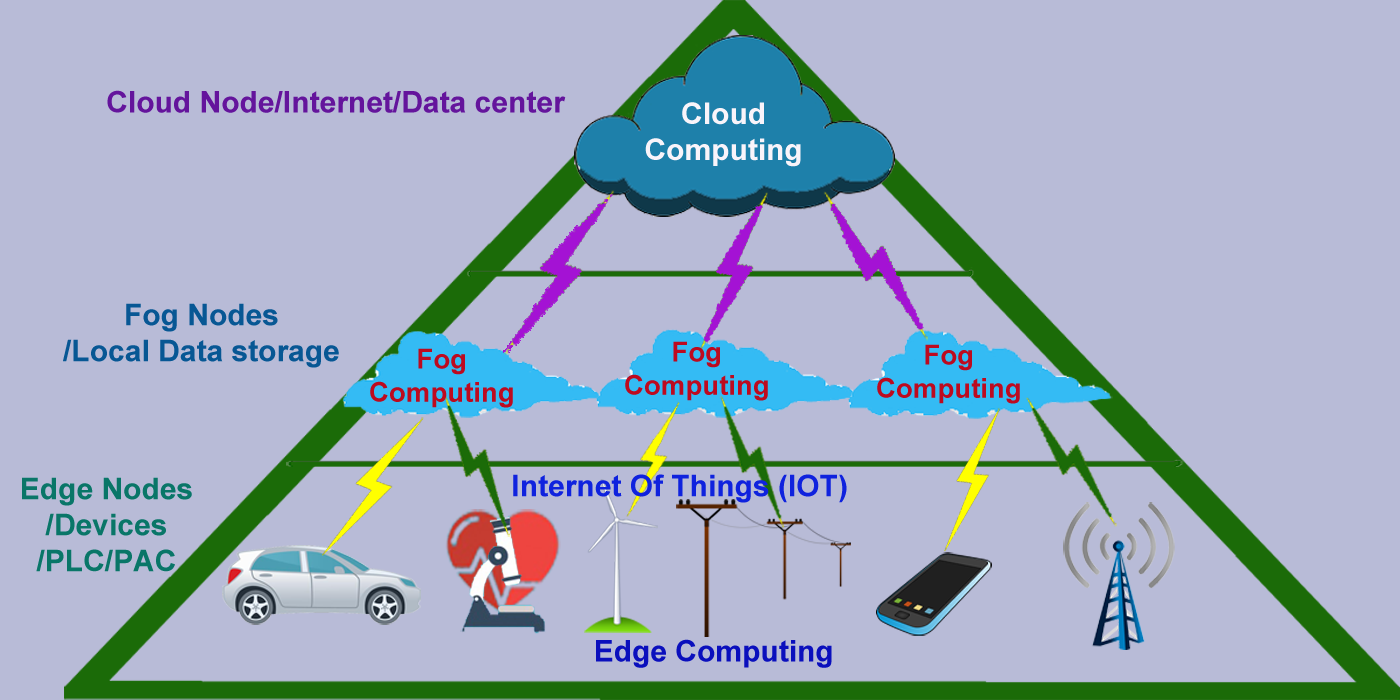
Fog Computing & Edge computing
FOG Computing–In context of IOT, if intelligence pushes d down to the local area network (LAN) and compute these data in IOT gateway or FOG node will reduce network latency risk. Fogging or FogNetwork is decentralized computing and stores data in most logical and efficient place between IOT device and the cloud.
In FOG computing, data transported from IOT to Cloud need many steps.
Signals from IOT is transported through wire to I/O point of device programmable automation controller(PLC). PLC execute control system program to automate system.
Control system program sends data to protocol gateway, which convert this data into a protocol, understand internet systems such as MQTT or HTTP.
At the end, data is send to fog node or IOT gateway on the LAN, which collects the data and preform analysis and computing on data. This even stores the data to transfer further to cloud network for later processing and intelligence.
Edge Computing — Edge computing refers to any computing infrastructure near to source of data (i.e. IOT device). So, Making IOT device smart and intelligent enough to take decision near to data gateway. The role of edge computing is to process data, store data in local device and transfer data to fog or cloud network. Above all processes are automated through PAC (Programmable automation controller) by executing board controlled system program. In edge computing, intelligence literally push to edge of network where our IOT device and outside network first connect to each other.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Twilio is a cloud based communication company that enables users to use standard web languages to build voice, VoIP, and SMS apps via a web API. Twilio provides a simple hosted API and markup language for businesses to quickly build scalable, reliable and advanced voice and SMS communications applications. Twilio based telephony infrastructure enable web programmer to integrate real time phone call, SMS or VOIP to their application.
Mulesoft provides cloud connector to integrate Twilio Api within Mulesoft. Mulesoft Cloud connector provides a simple and easy way to integrate with these Twilio APIs, and then use them as services within Mulesoft. Mulesoft-Twilio connector provides a platform for developer to develop and integrate their application easily and quickly with Twilio.
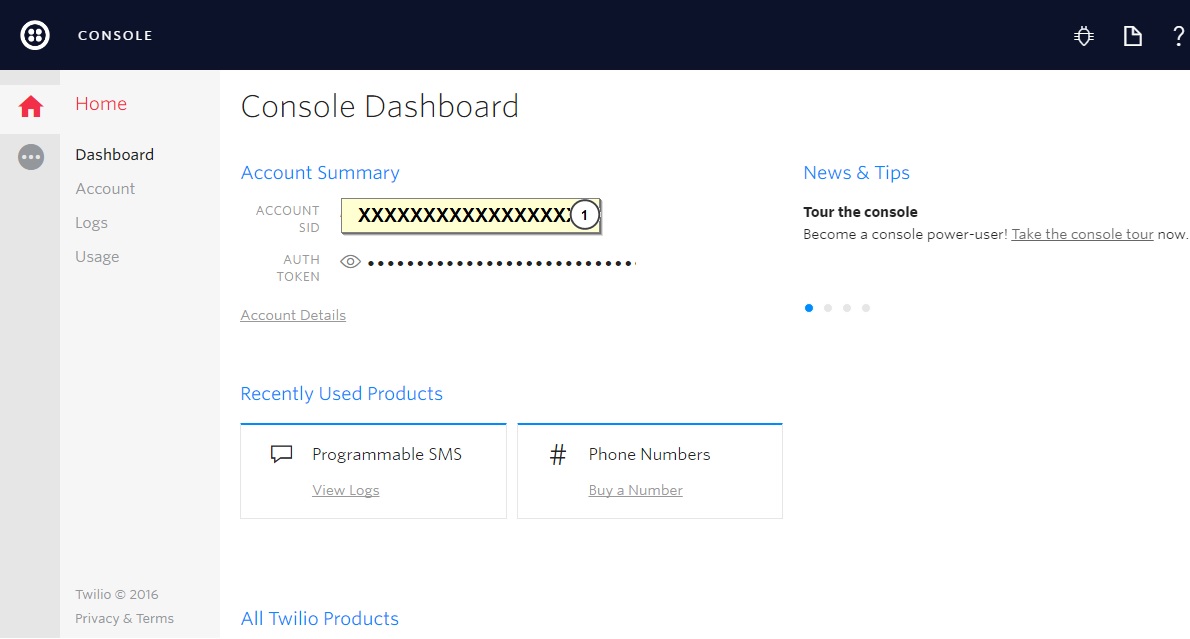
Before start integration of Mulesoft with Twilio, create your Twilio account and get “ACCOUNT SID” and “AUTH TOKEN”.
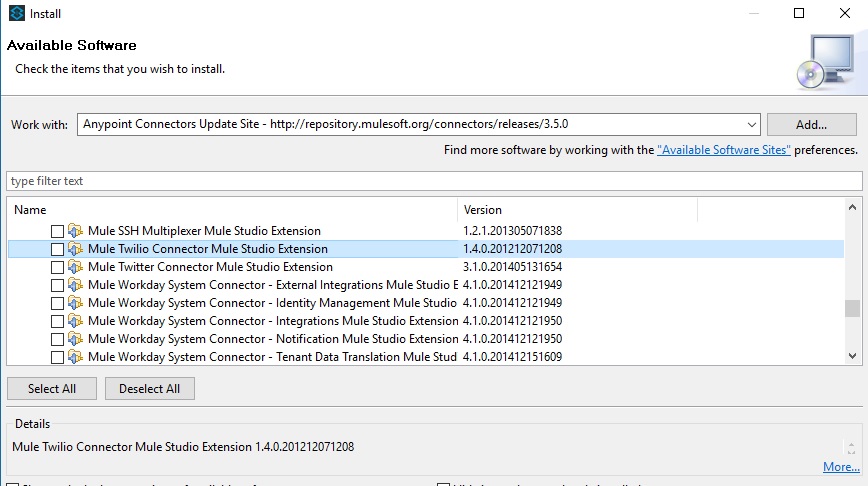
Now download and install Twilio connector into Anypoint studio.
Anypoint Studio –>Help –>Install New Software
Configure pom.xml to pull Twilio jar dependency in maven based project.
Add plugin in plugin section and dependency in pom.xml file. This section will also add into pom.xml file when Twilio connector drag into AnypointStudio canvas and use it into flow.
In above code TwilioSID and TwilioAuthToken are coming from Twilio account.
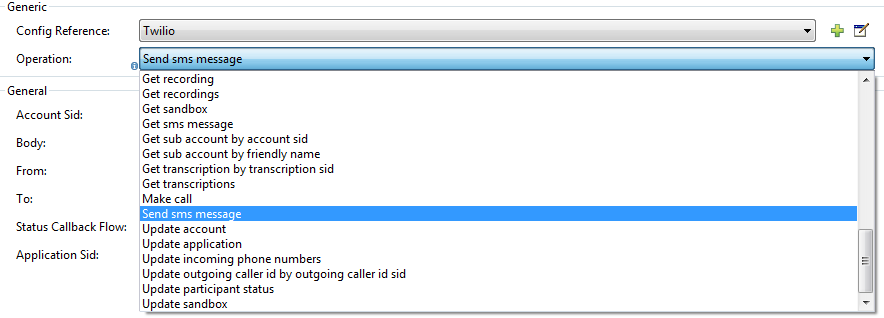
Mulesoft Twilio connector provides a number of methods to integrate with your application. Below image show some of methods expose by Mulesoft-Twilio connector.
I am using “send SMS message” method form Mulesoft-Twilio connector for my example.
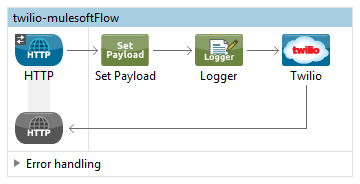
Now you can integrate Twilio to send SMS with your application. Here is example code.
<logger message="#[payload.recipientPhoneNumber]" level="INFO" doc:name="Logger"/>
<twilio:send-sms-message config-ref="Twilio" accountSid="${TwilioSID}" body="Hello World Sending SMS from Twilio" from="+15555555555" to="#[payload.recipientPhoneNumber]" doc:name="Twilio"/>
Twilio API does not support bulk SMS for recipient. So, to initiate messages to a list of recipients, you must make a request for each number to which you would like to send a message. The best way to do this is to build an array of the recipients and iterate through each phone number.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.
Initially when REST was introduced there was always challenge to validate your request against prerequisite requirement. This was available in SOAP web services as XSD schema validation but it was not available in REST webservice. Architect and developer had to face the challeng to implement some kind of schema to validate their request.
YAML based RAML (Restful API modeling Language) was introduced in 2013. RAML gives flexibility to define schema to validation request/response. This breakthrough helps Architect and developer to define schema for REST API to validate request/response.
RAML schema validation can be defined in two formats.
1) XSD Based
2) Json Based.
Schema validation can be defined in two ways inside RAML
1) Inline schema definition
2) XSD or json schema definition file.
Schema definition can be defined in schema tag within RAML file. “!Include” tag uses to include schema file for file based schema definition within RAML.
Json based schema definition
/car: post:description:Getting car info from Car Applicationbody: application/json:schema: !includeschemas/cars-schema-request.json
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.